So far, we’ve concentrated on descriptive and exploratory data analysis.
At this stage of the course we seek to answer predictive questions about data.
Today we cover classification fundamentals: data preprocessing, and prediction using observed data.
Next class will focus on how to evaluate prediction accuracy and improving the classifier for optimal results.
Classification
Classification involves predicting the value of a categorical variable (AKA class or label) using one or more variables.
Classification is a form of supervised learning since we seek to learn from labelled data.
Generally, a classifier assigns an observation without a known class to a class on the basis of how similar it is to other observations for which we do know the class.
How Classification Works
Classification relies on numeric or categorical variables, often referred to as features or attributes and denoted by \(X\), of the data points.
The process involves training a classification model, using the labeled training data.
Once the model is trained, it can be used to make predictions about the class or category of new, unlabeled data points.
Types of Classification:
In binary classification, there are two possible classes or outcomes.
e.g., “Yes” or “No,” “Spam” or “Not Spam.”
Multiclass classification involves more than two classes.
e.g., “Cat,” “Dog,” “Bird,” or “Fish”
Oftentimes, these categories are coded as integers in our data set, e.g. 1 = male, 0 = female
Methods for Classification
While there are many possible methods for classification.
In this course, we will focus on the widely used K-nearest neighbors (KNN) algorithm1\(^{,}\)2
In your future studies, you might encounter decision trees, support vector machines (SVMs), logistic regression, neural networks, and more, …
Example: Simulation
Code
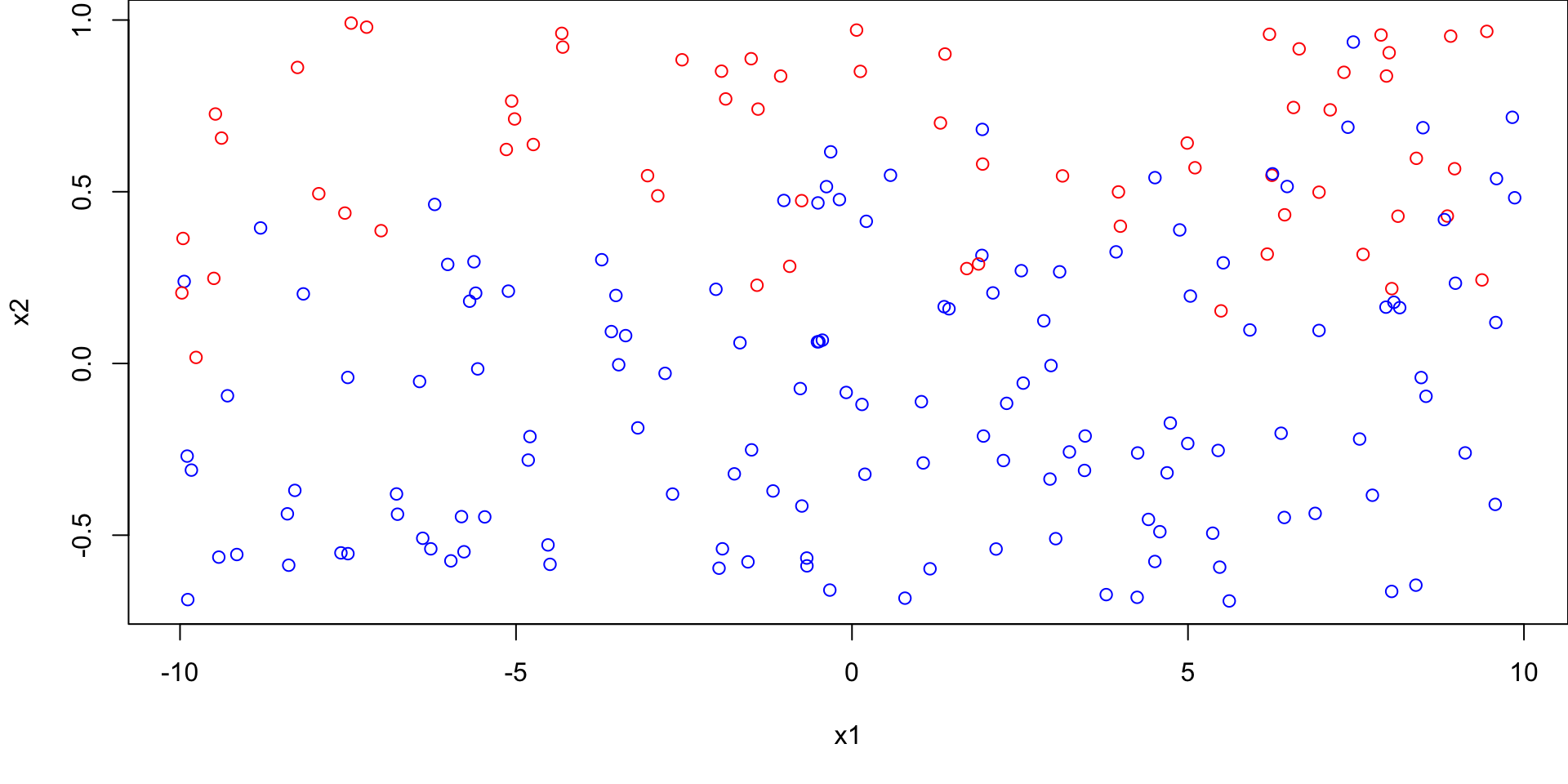
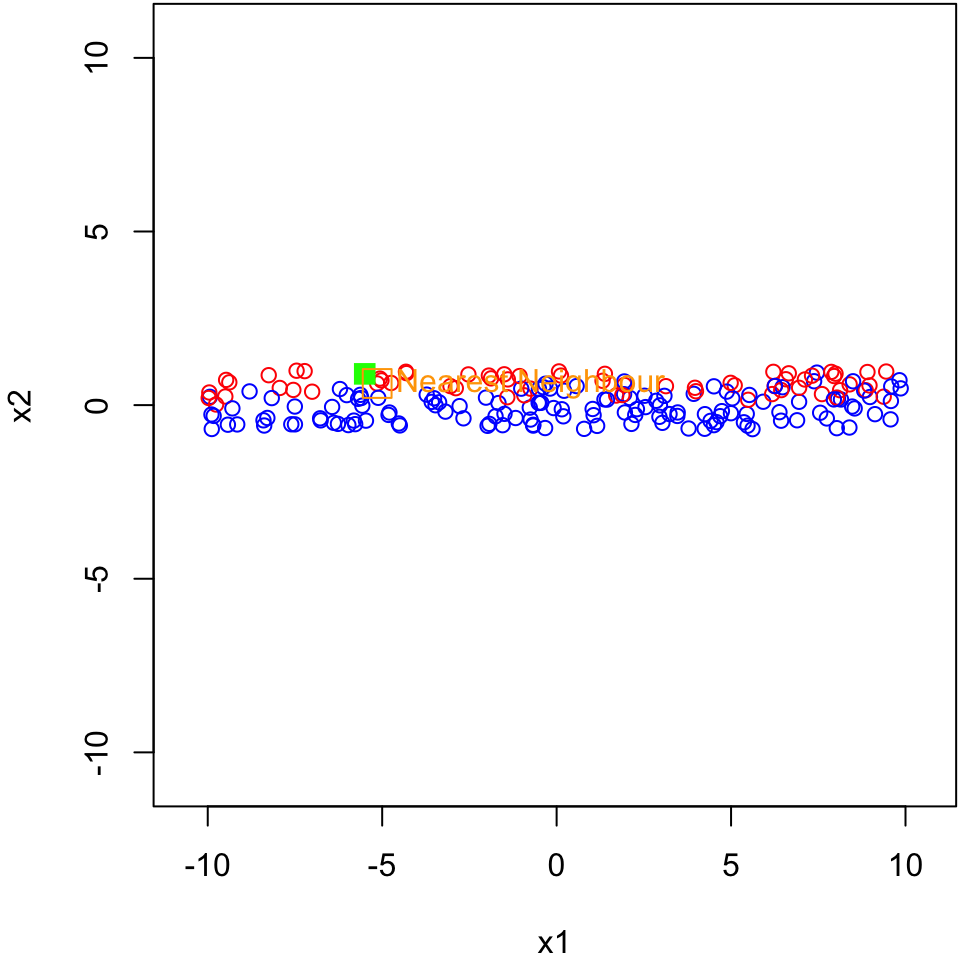
# for reproducibilityset.seed(4623)# generate some random pointsx1 <-runif(200, -10, 10)x2 <-runif(200, -0.7, 1)# assign class labels according to the x2 valueclas <-rep(NA, length(x2))for(i in1:length(x2)){ clas[i] <-sample(1:2, size =1, prob =c(max(0, x2[i]), min(1- x2[i], 1)))}par(mar=c(5.1,4.1,0,0))plot(x1, x2, col=c("red", "blue")[clas], pch =1)
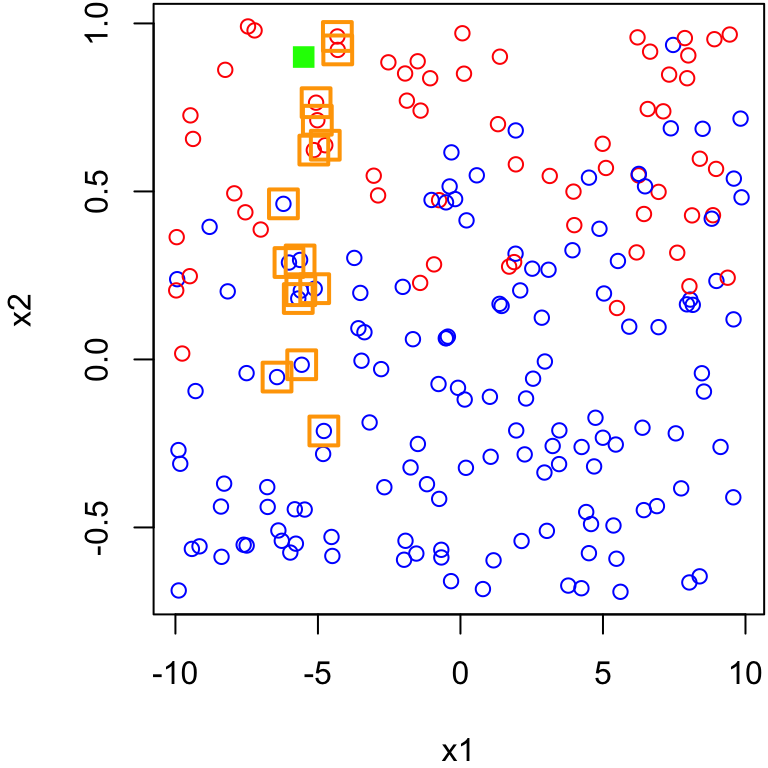
Suppose we have training set with two numeric features (\(X_1\) and \(X_2\)) having two possible classes: 1 (coloured in red) or 2 (coloured in blue)
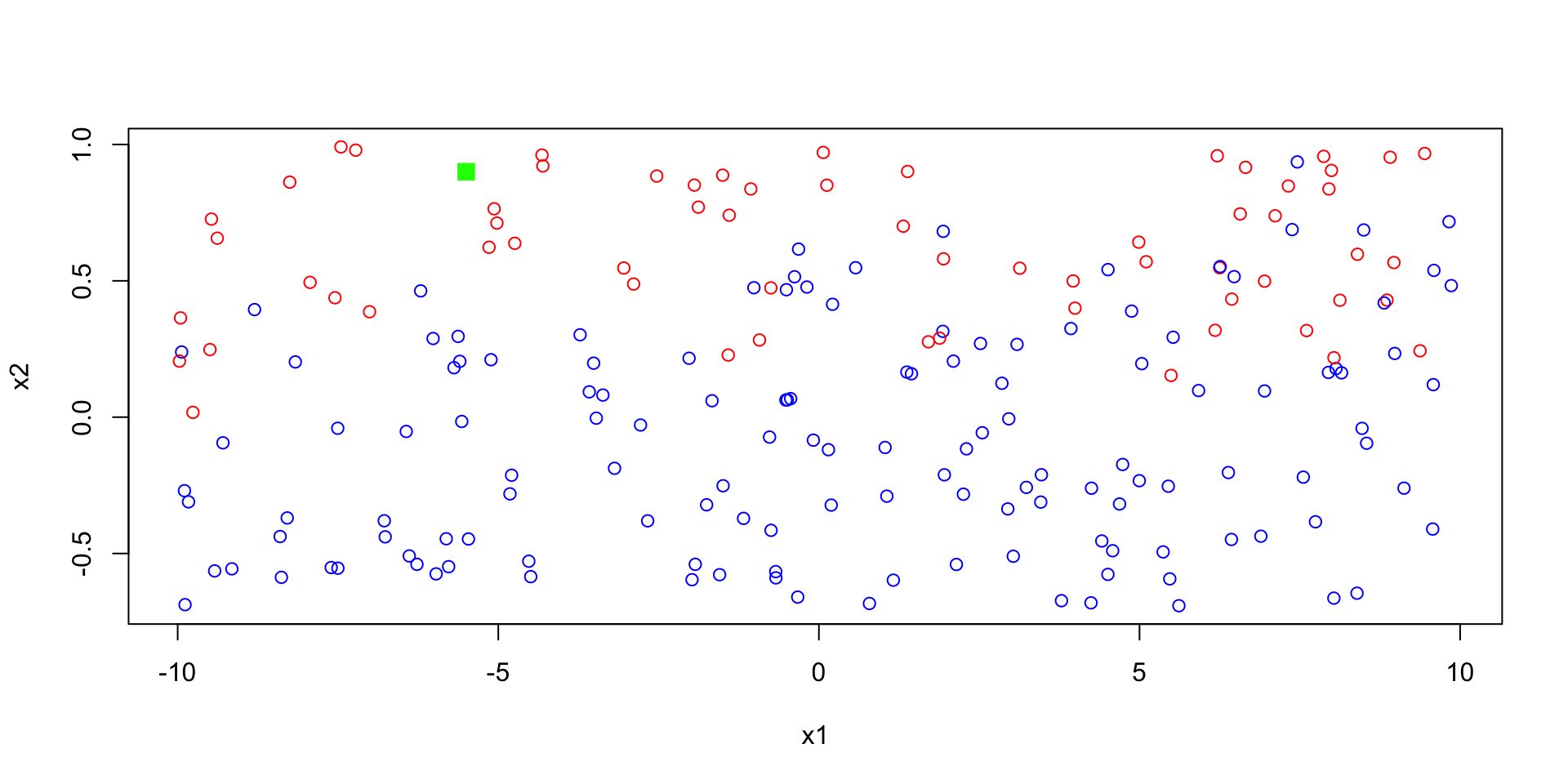
Green point
Suppose we have a new observation (ploted in green) and we would like to predict if that point is 1 (red) or 2 (blue). What would you predict?
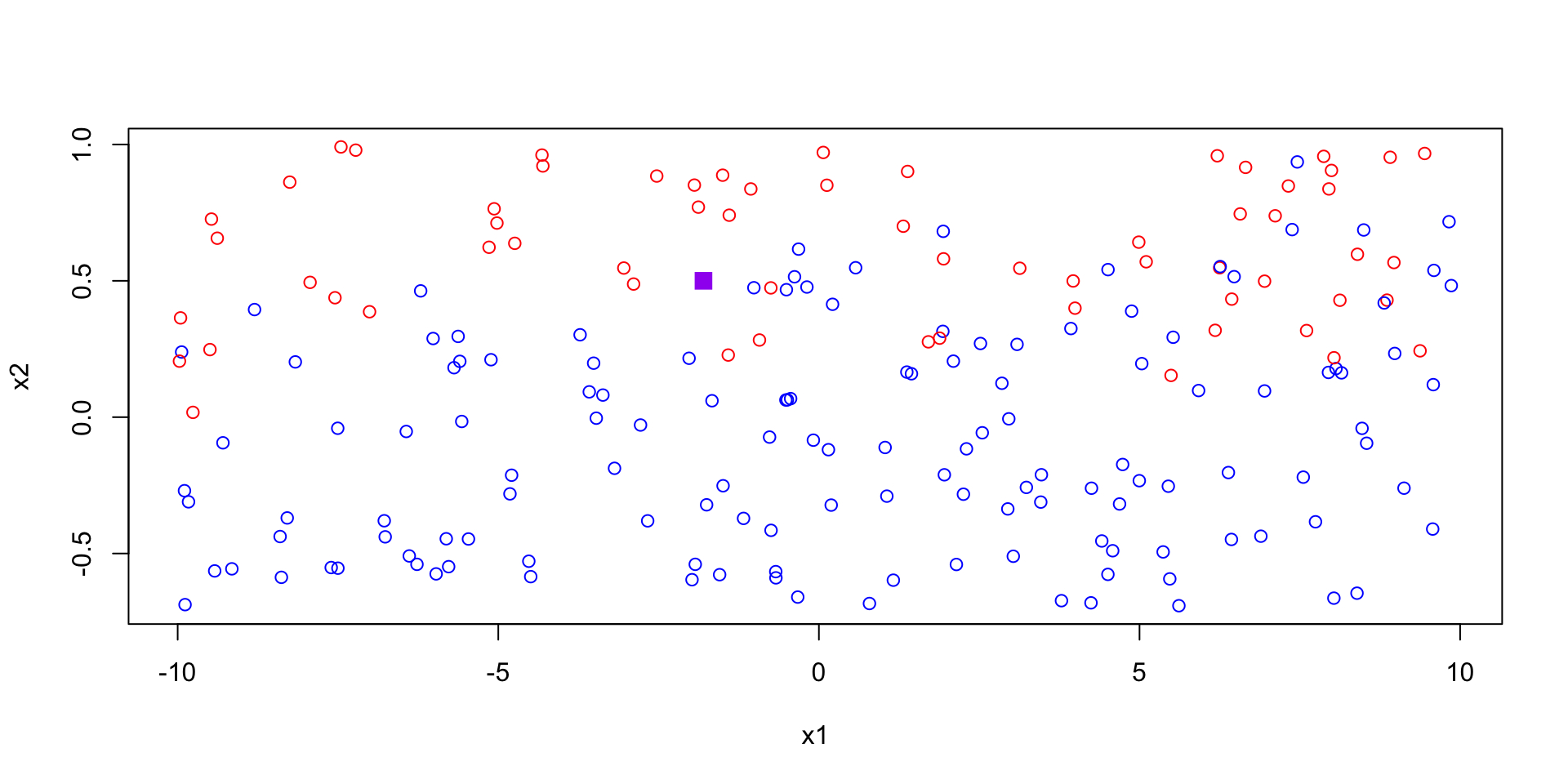
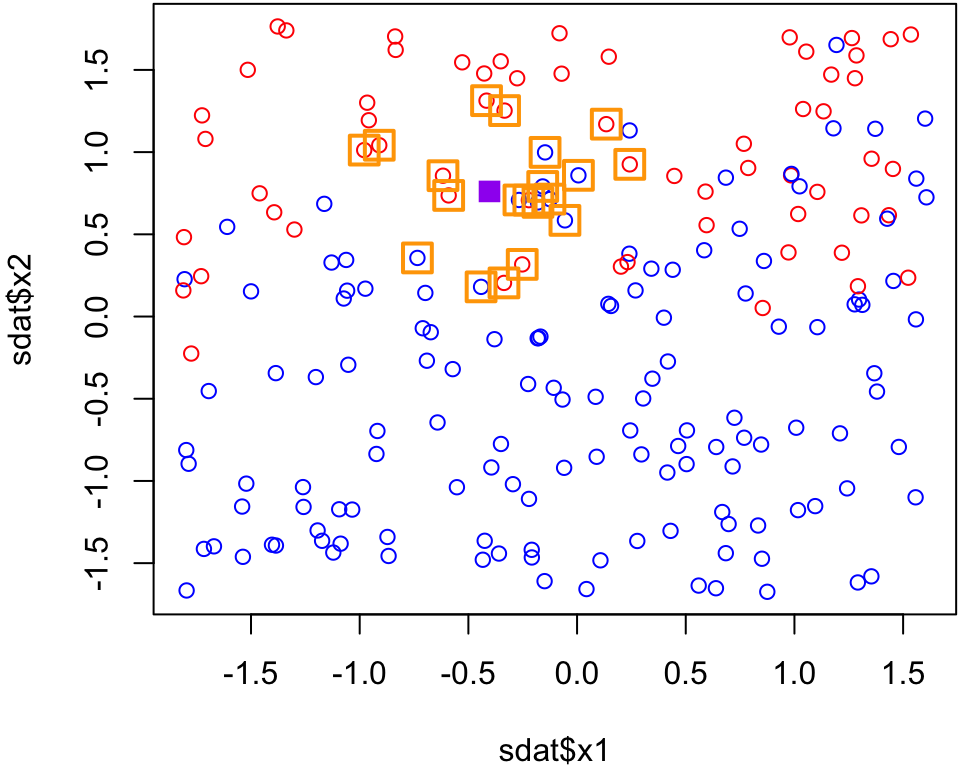
Purple point
Suppose we have a new observation (ploted in purple) and we would like to predict if that point is 1 (red) or 2 (blue). What would you predict?
Concept of KNN
KNN is a distance-based algorithm.
It works on the principle that data points that are close to each other in the feature space are likely to belong to the same class.
It measures the “closeness” or similarity between data points using a distance metric (most commonly Euclidean)
Euclidean Distance (2D)
The Euclidean distance between observations \(\boldsymbol p = (p_1, p_2)\) and \(\boldsymbol q = (q_1, q_2)\) is calculated as
Using the Pythagorean theorem to compute 2D Euclidean distance [src]
Euclidean Distance
The Euclidean (or straight-line) distance between observations \(\boldsymbol x = (x_{1}, x_{2}, \dots x_{p})\) and \(\boldsymbol y = (y_{1}, y_{2}, \dots y_{p})\) is calculated as \[d(\boldsymbol x, \boldsymbol y) = \sqrt{\sum_{i=1}^p (x_{i} - y_{i})^2}\]
Steps of KNN Classification
Given positive integer \(k\) (chosen by user) and observation \(\boldsymbol x\):
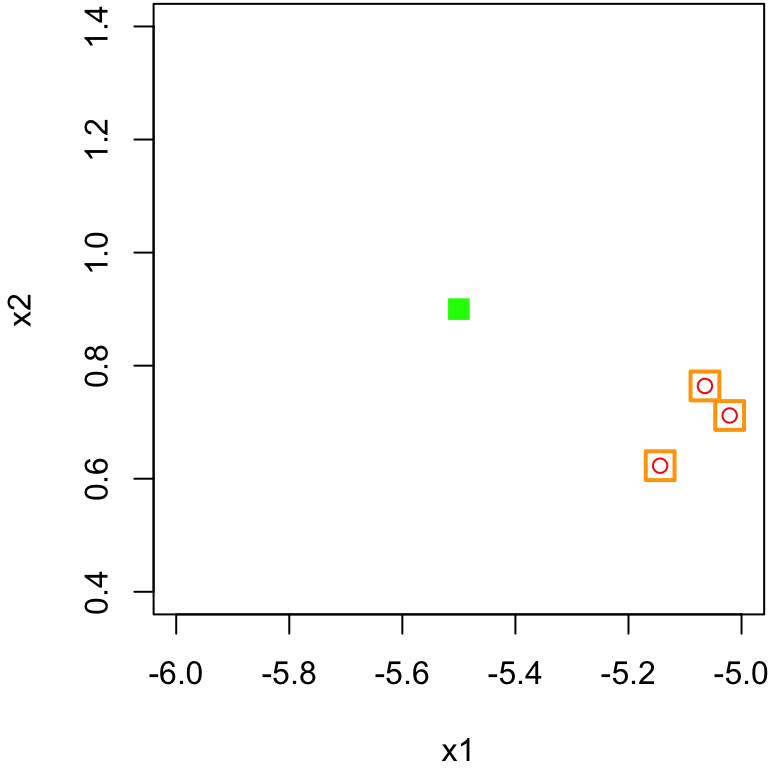
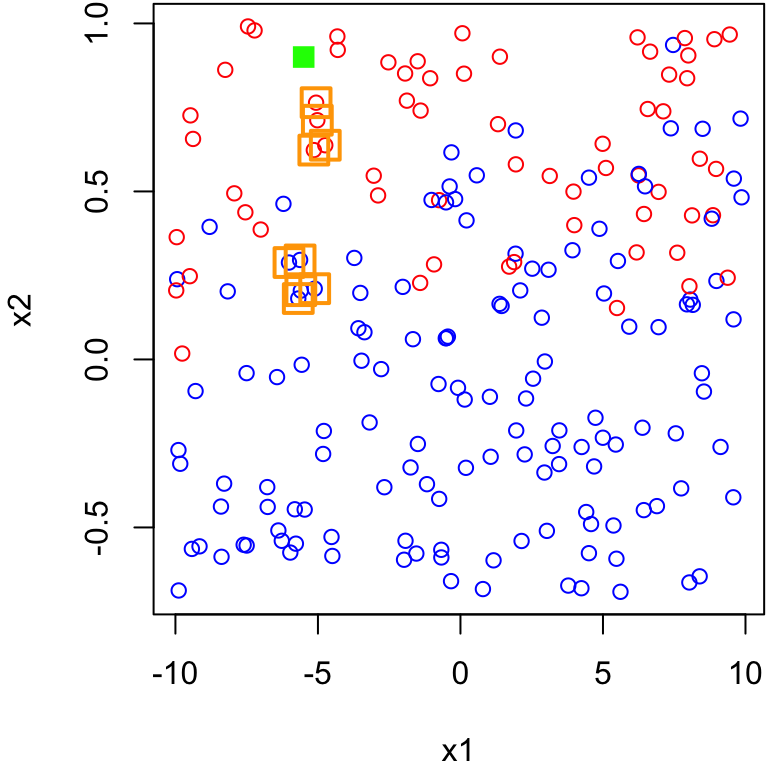
Nearest Neighbours: Identify the \(k\) closest points to \(\boldsymbol x\) in training feature space. These are called the nearest neighbors; we denoted their set by \(\mathcal N_0\)
Majority Voting: The class label that occurs most frequently among the \(k\)-nearest neighbors is assigned to \(\boldsymbol x\).
R implementation
To demo knn classification we will be using the knn function from the class package performs1
library("class")knn(train, test, cl, k)
train matrix or data frame of training set cases.
test matrix or data frame of test set cases.
cl factor of true classifications of training set
k number of neighbours considered.
k Nearest Neighbours Example
Let’s apply this algorithm to the simulated data considered previously.
As described here, the user needs to specify \(k\), the number of nearest neighbours to consider.
We will discuss the important issue of how which \(k\) to use next lecture. For now, let’s try a few options and see how that affects our predictions.
More specifically, we will fit knn for \(k = 20, 15, 9, 3\) and \(1\)
Since 5 of the 9 nearest neighbours are blue and only 4 of the 9 nearest neighbours are red, the majority vode for the green point is now blue.
15 nearest neighbours
k =15tabk = dat.dist |>slice_min(dist_from_new, n = k) |>select(clas) |>as.vector() |>table()names(tabk) =c("red", "blue")tabk
red blue
6 9
Since 9 of the 15 nearest neighbours are blue and only 6 of the 15 nearest neighbours are red, the majority vode for the green point is blue when \(k\) = 15.
20 nearest neighbours
k =20tabk = dat.dist |>slice_min(dist_from_new, n = k) |>select(clas) |>as.vector() |>table()names(tabk) =c("red", "blue")tabk
red blue
6 14
Since 14 of the 20 nearest neighbours are blue and only 6 of the 20 nearest neighbours are red, the majority vode for the green point is blue when \(k\) = 20.
KNN predictions for Green point
g.3=knn(dat, test = greenpt, cl = clas, k =3)g.3# 1 = red
[1] 1
Levels: 1 2
g.9=knn(dat, test = greenpt, cl = clas, k =9)g.9# 2 = blue
[1] 2
Levels: 1 2
g.15=knn(dat, test = greenpt, cl = clas, k =15)g.15# 2 = blue
[1] 2
Levels: 1 2
g.20=knn(dat, test = greenpt, cl = clas, k =20)g.20# 2 = blue
[1] 2
Levels: 1 2
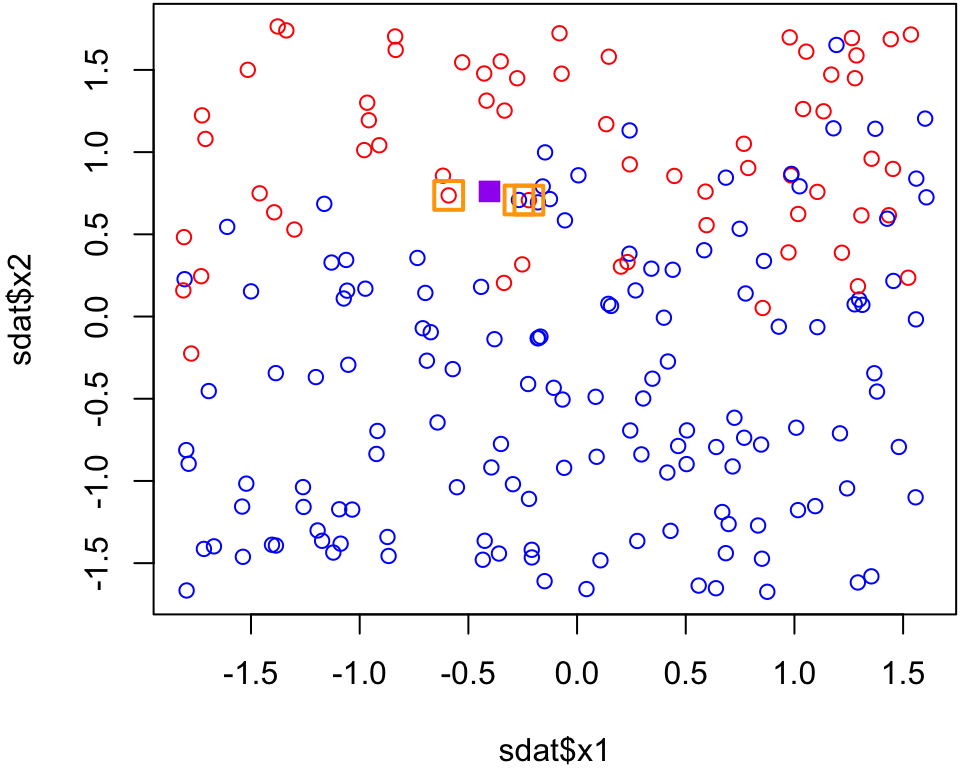
KNN predictions for Purple point
p.1=knn(dat, test = purplept, cl = clas, k =3)p.1# 1 = red
[1] 1
Levels: 1 2
p.3=knn(dat, test = purplept, cl = clas, k =3)p.3# 1 = red
[1] 1
Levels: 1 2
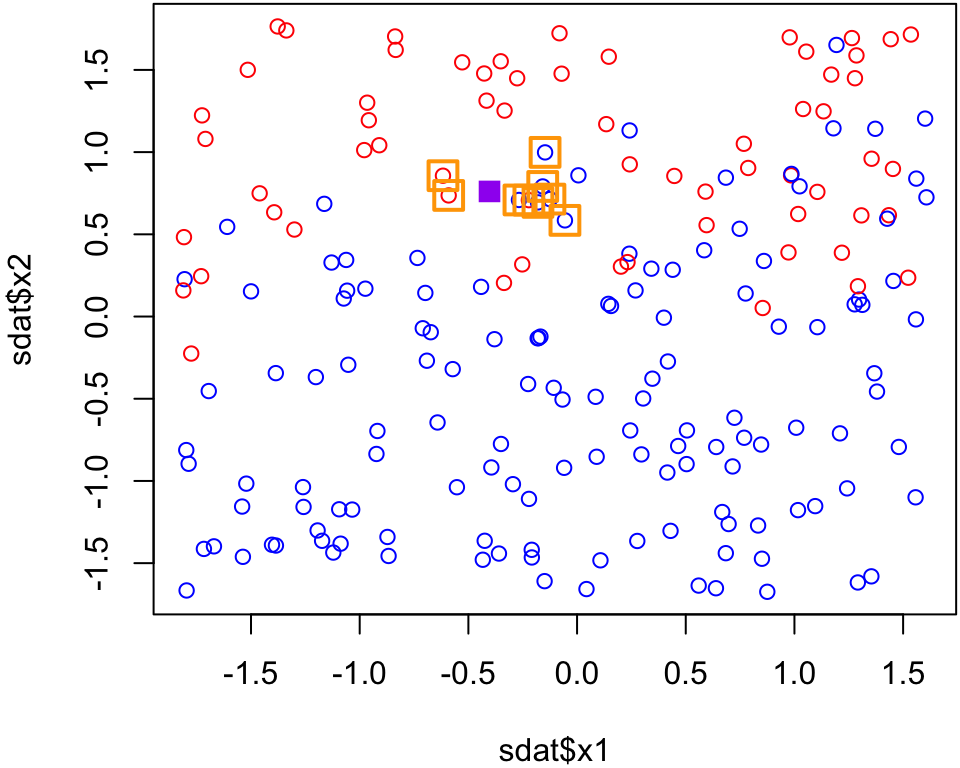
p.9=knn(dat, test = purplept, cl = clas, k =9)p.9# 1 = red
[1] 1
Levels: 1 2
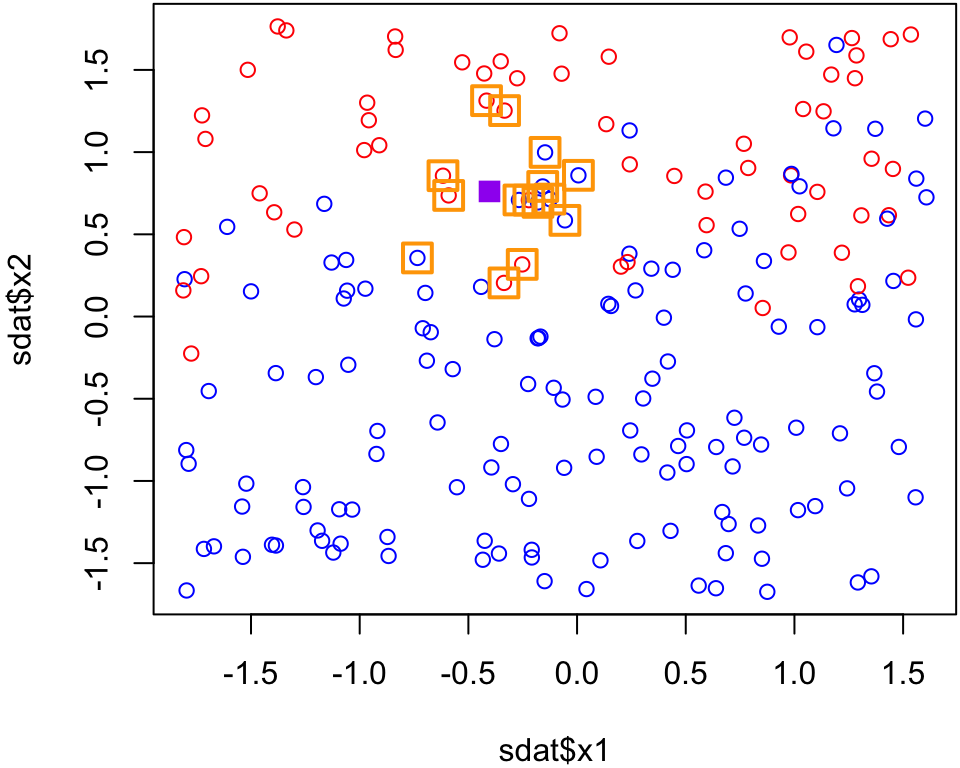
p.15=knn(dat, test = purplept, cl = clas, k =15)p.15# 1 = red
[1] 1
Levels: 1 2
p.20=knn(dat, test = purplept, cl = clas, k =20)p.20# 1 = red
[1] 1
Levels: 1 2
Choosing k
A key component of a “good” KNN classifier is determined by how we choose \(k\).
\(k\) in a user-defined input to our algorithm which we can set anywhere from 1 to \(n\) (the number of points in our training set)
Question What would happen if \(k\) was set equal to \(n\)?
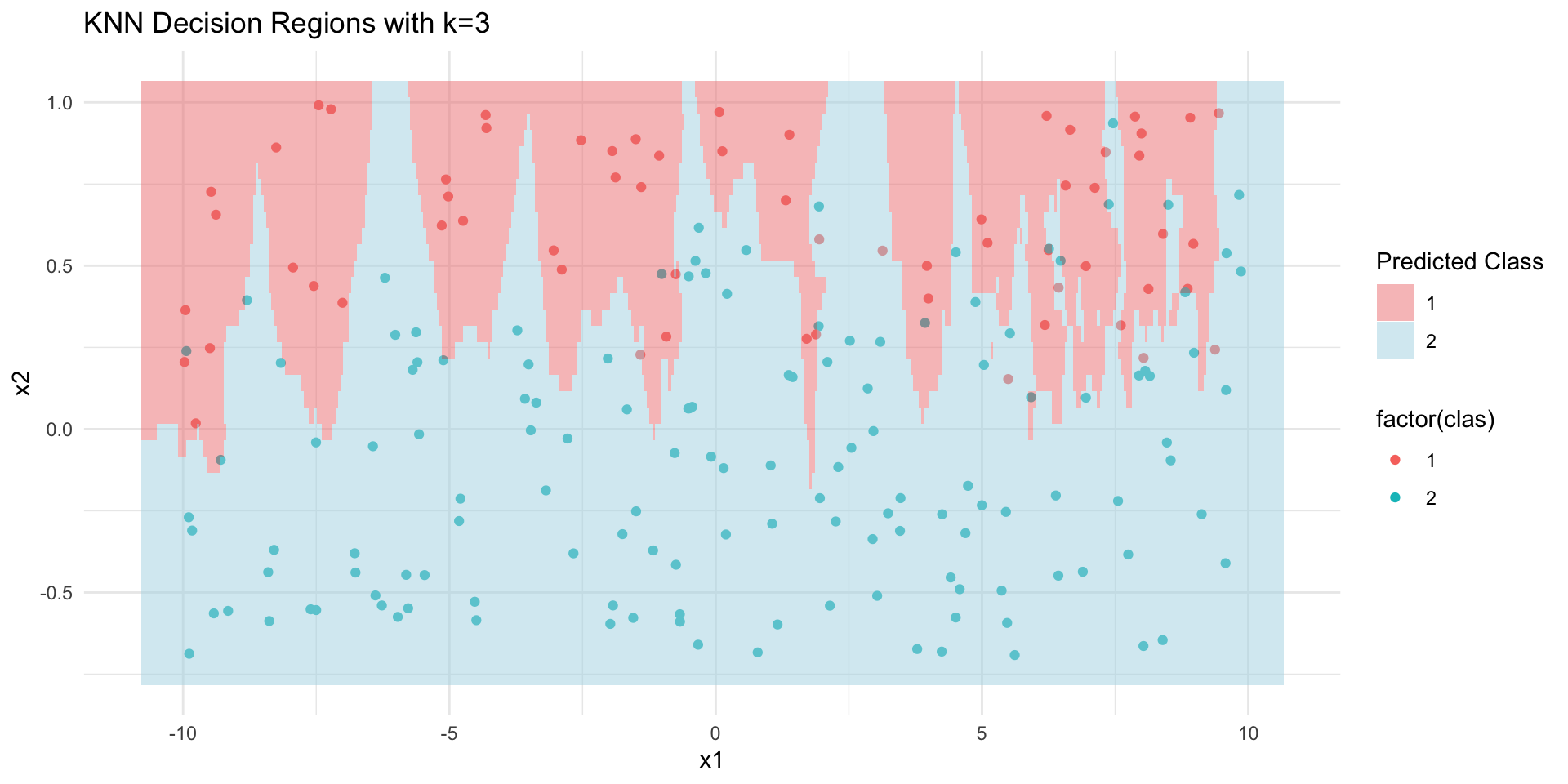
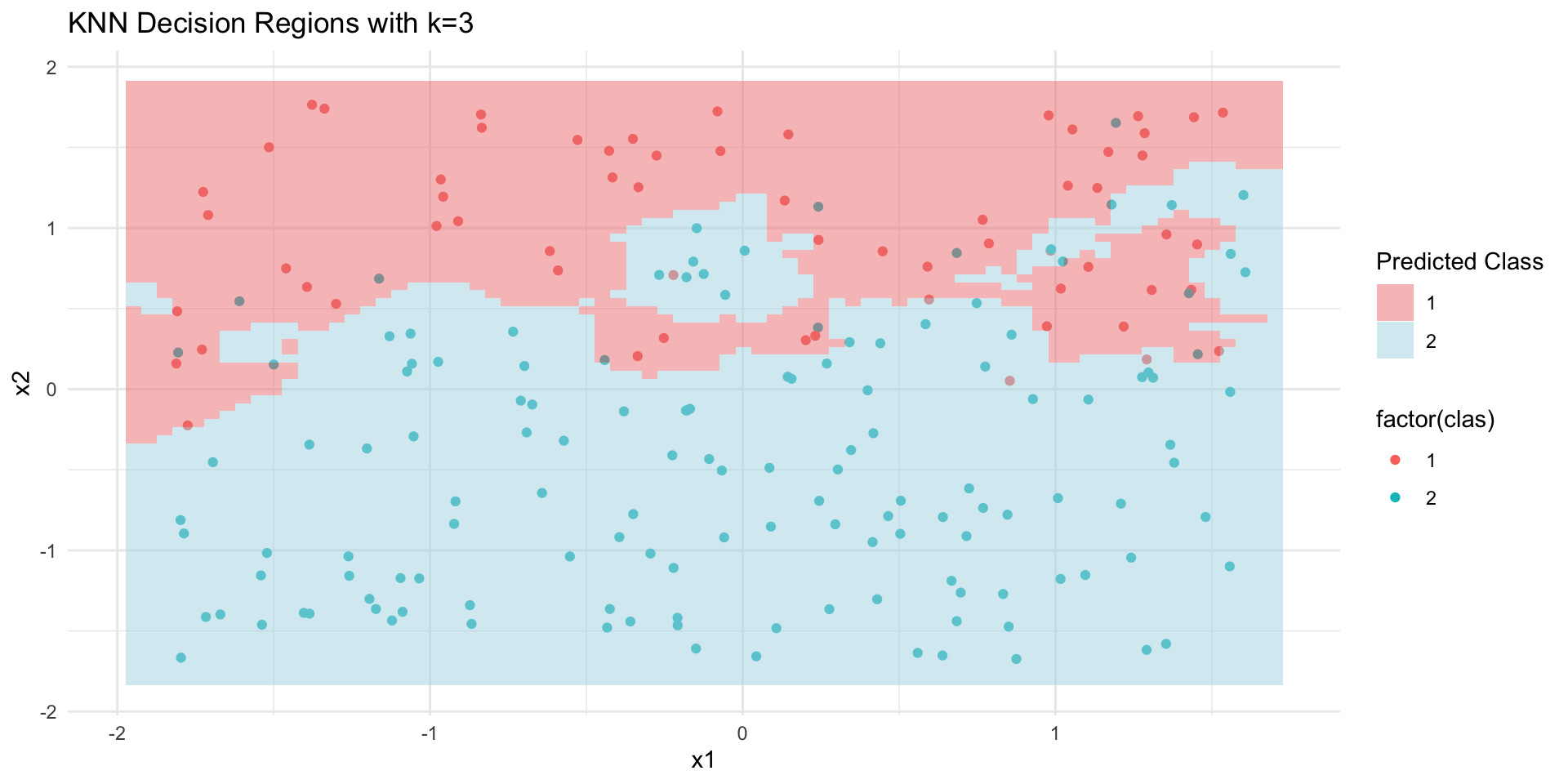
KNN Decision regions
KNN decision regions. Any new points in the shaded red areas will be classified as red. Any new points in the shaded blue areas will be classified as blue. Compare with scaled.
Comment
When using KNN classification, the scale of each variable (i.e., its size and range of values) matters.
Since the classifier predicts classes by identifying observations nearest to it, any variables with a large scale will have a much larger effect than variables with a small scale.
But just because a variable has a large scale doesn’t mean that it is more important for making accurate predictions.
Scale Matters
Example Suppose we want to predict the type of job based on salary (in dollars) and years of education
When we compute the neighbor distances, a difference of $1000 is huge compared to a difference of 10 years of education.
But for our conceptual 10 years of education is huge compared to a difference of $1000 in yearly salary!
Center (sometimes) matters
In many other predictive models, the center of each variable (e.g., its mean) matters as well.
For example, changing a temperature variable from degrees Kelvin to degrees Celsius would shift the variable by 273
Although this doesn’t affect the KNN classification algorithm, this large shift can change the outcome of using many other predictive models.
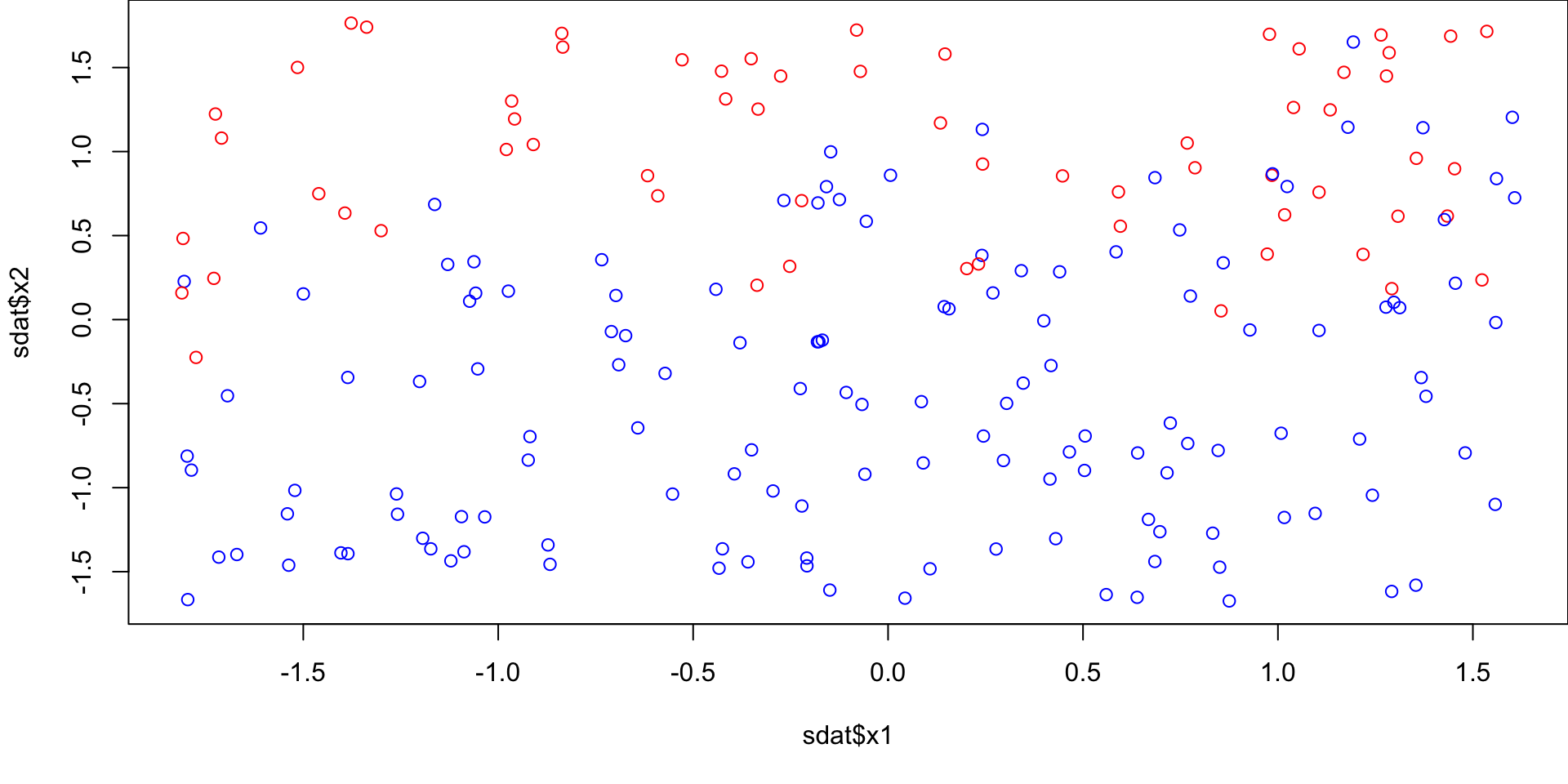
Data preprocessing
Because of the reasons stated before, it is common practice to standardized our data.
For each observed value of the variable, we subtract the mean (the average, which quantifies the “central” value of a set of numbers) and divide by the standard deviation (a number quantifying how spread out values are).
Now the data is said to be standardized, and all features will have a mean of 0 and a standard deviation of 1.
Standardized Euclidean Distance
In other words we scale and center our data to have mean 0, variance 1 via
KNN decision regions. Any new points in the shaded red areas will be classified as red. Any new points in the shaded blue areas will be classified as blue. Compare with unscaled.
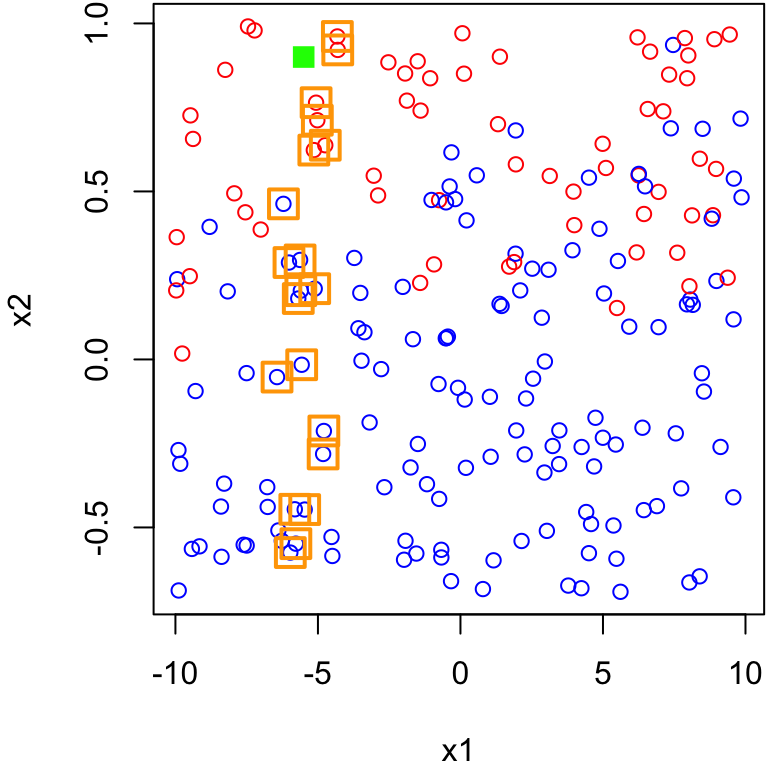
3 nearest neighbours Purple point
Since 2 of the 3 nearest neighbours are red and only 1 of the 3 nearest neighbours are blue, the majority vode for the purple point is red when \(k\) = 3.
9 nearest neighbours Purple point
Since 6 of the 9 nearest neighbours are blue and only 3 of the 9 nearest neighbours are red, the majority vode for the purple point is blue when \(k\) = 9.
15 nearest neighbours Purple point
Since 8 of the 15 nearest neighbours are blue and only 7 of the 15 nearest neighbours are red, the majority vode for the purple point is blue when \(k\) = 15.
20 nearest neighbours Purple point
Since 11 of the 20 nearest neighbours are red and only 9 of the 20 nearest neighbours are blue, the majority vode for the purple point is red when \(k\) = 20.
Balance
A potential issue for a classifier is class imbalance, i.e., when one label is much more common than another.
Since classifiers like KNN use the labels of nearby points to predict the label of a new point, if there are many more data points with one label overall, the algorithm is more likely to pick that label in general
Class imbalance is actually quite a common and important problem, e.g., rare disease diagnosis, malicious email detection
Solution
Despite the simplicity of the problem, solving it in a statistically sound manner is actually fairly nuanced, and a careful treatment would require a lot more detail and mathematics than we will cover in this course.
For the present purposes, it will suffice to either rebalance the data by:
oversampling the underrepresented class.
undersampling the overrepresented class.
Simulation revisited
For instance we have more blue points than red points:
If we are adopting option 2. on the previous slide, we could create a data set with, say, 63 in both the red class and blue class and repeat the analysis.
Handling missing data properly is very challenging and generally relies on expert knowledge about the data, setting, and how the data were collected.
In this course, we assume missing entries are just “randomly missing”,
To handle these observations we’ll simply remove the row having NAs (with, say, the drop_na() function)
Warning
Missing entries can be informative since the absence of values maybe have some underlying significance.
e.g., survey participants from a marginalized group of people may be less likely to respond to certain kinds of questions if they fear that answering honestly will come with negative consequences.
If we simply throw away data with missing entries, we would bias analysis by inadvertently removing many members of that group of respondents.
Final comments
We have gone through some very basic code in this lecture and dealt mostly with the concepts
It will be very important that you attend labs this week and get a handle of the tidymodel syntax for running KNN within tidyvers.
It is also highly recommended that you go through the examples in Chapter 5 of your textbook.

![[src]](https://en.wikipedia.org/wiki/Euclidean_distance#/media/File:Euclidean_distance_2d.svg){kind=link}
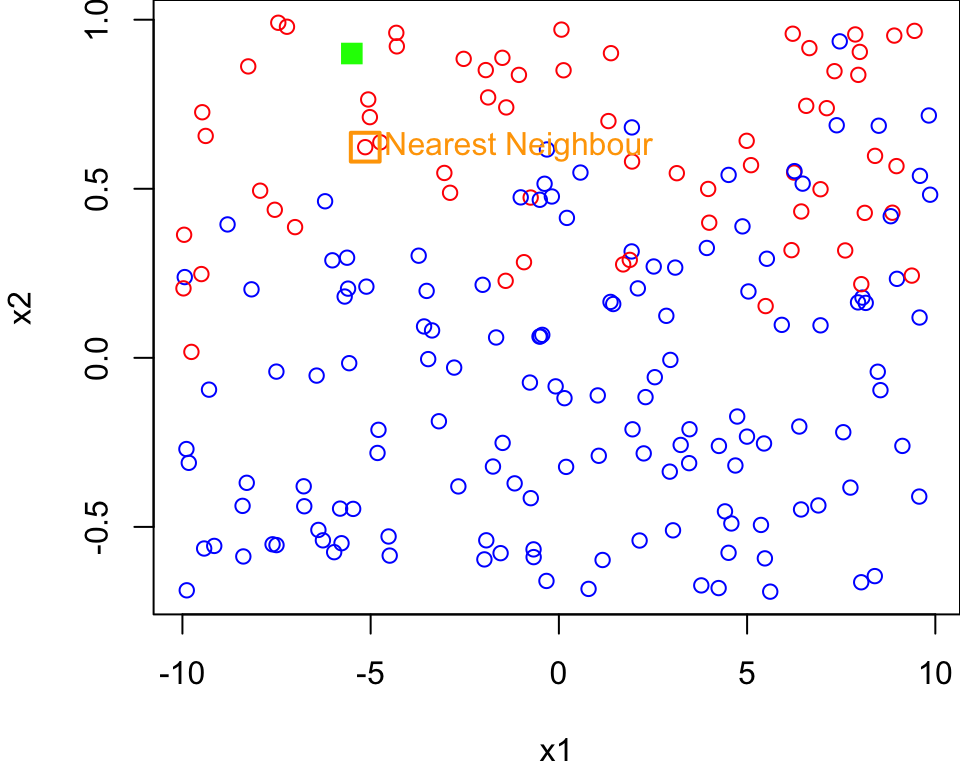
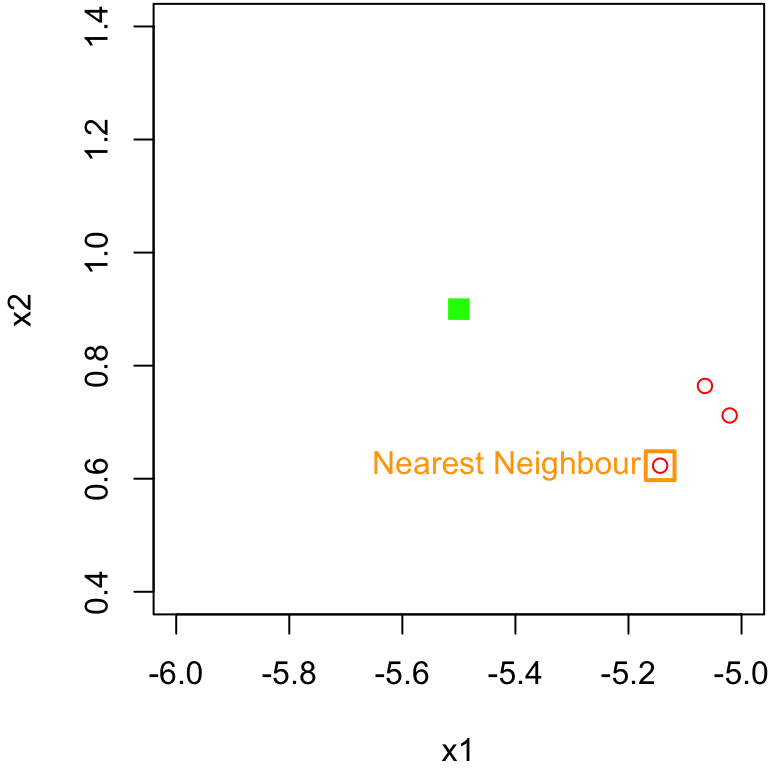
Comment on scale
It may seem confusing visually why this point is the nearest neighbour to the green square.
It makes sense once you consider the scale of the
x1feature.The range of
x1on the x-axis is 20, whereas the scale ofx2on the y-axis is 1.5Using the same scale we can see why …