# Example loading a CSV file
data <- read.csv("data.csv")`
data <- read.table("file.txt", sep=";")
data <- read.csv("url/data/data.csv")Review Session 2
DATA 101: Making Prediction with Data
Introduction
Today, we will review the concepts covered in lecture 5 through 8 inclusive and lab 4.
Data Visualization (base R)
Data Visualization (using ggplot)
Data Wrangling in Base R (lecture 4 quick review)
Data wrangling in base R is a fundamental aspect of data analysis and manipulation in the R programming language. However, R provides a wide range of functions and packages to help you perform data wrangling tasks effectively. For example:
Load Data: for loading your data into R
Data Inspection examing your data. For example, check for missing values, and understand its structure.
head(data) # View the first few rows str(data) # Structure of the data summary(data) # Summary statistics`Data Cleaning: examples:
- Handle missing values using functions like
is.na(),na.omit(), or impute them with relevant values. - Filter or remove rows and columns using functions like
subset()or[ ]. - Correct data types using functions like
as.numeric(),as.character(), oras.Date().
- Handle missing values using functions like
Data Transformation: create new variables/columns or recode existing ones
- Recode values using functions like
ifelse()
# Example: Create a new variable data <- transform(data, new_column = old_column * 2)- Recode values using functions like
Aggregation and Grouping: perform aggregation and calculate summary statistics.
# Example: Calculate the mean by a grouping variable library(dplyr) data %>% group_by(grouping_variable) %>% summarize(mean_value = mean(numeric_variable))Sorting and Ordering: using functions like
order(),sort()in base orarrange()from thedplyrpackage.# Example: Sort data by a variable in ascending order data <- data[order(data$variable_name), ] # doing the same thing using dplyr (a tidyverse pacakge) data <- data %>% arrange(variable_name)Data Visualization: Use packages like
ggplot2or base R graphics functions to create visualizations to explore and communicate your data.library(ggplot2) # make a simple scatterplot ggplot(data = your_data, aes(x = x_variable, y = y_variable)) + geom_point()Exporting Data: Save your processed data using functions like
write.csv()or other export functions.write.csv(data, "processed_data.csv")Documentation: Keep detailed notes or scripts with comments to document your data wrangling process. We use complete our analysis in an R Markdown (with
.rmdextension) document.
R Markdown
R Markdown is a combination of plain text and code that allows you to integrate narrative text, code, and the results of code execution (such as tables and charts) into a single document. These documents are processed by R and can be rendered in various output formats, including HTML, PDF, Word, and more. These documents are:
- fully reproducible; each time you knit the analysis is ran from the beginning
- simple markdown syntax for text
- code goes into “chunks” or “inline” R code
Data Wrangling with Tidyverse
While there are many baseline functions that can aid in our data wrangling tasks (e.g. read.csv, str(), subset) we will typically call to tidyvserse package to enhance and streamline data analysis, data manipulation, and data visualization. Tidyverse is a set of packages developed together following a common set of principles. The “tidy” data philosophy, where each variable has its own column, each observation has its own row code clarity and reproducibility through common functional structure use of pipe |> (or %>%) to improve code development and readability. When we load this meta-package, it loads the following collection packages:
dplyr: data manipulationforcats: functions for working with factorsggplot2: data visualizationlubridate: handles dates and timespurrr: code optimization and functional programmingreadr: open and organize the datastringr: functions for working with string datatibble: alternative to data.frame classtidyr: used for data tidying
Piping Operator
The pipe operator, |> from base and %>% operator (from tidyverse) is a way to chain together a sequence of operations, improve readability, and avoid creating and storing multiple intermediate objects. It takes the result of one expression on the left-hand side and feeds it as the first argument to a function on the right-hand side. You can keep on applying the pipe to a series of operations to your data in a clear and sequential manner.
Control + Shift + M is a handy keyboard shortcut for typing the
%>%pipe operator
✅ Example :
library(dplyr)
data <- data %>%
filter(column1 > 5) %>%
group_by(column2) %>%
summarise(mean_value = mean(column3))Compare that to how we would have done this in base R 🙅🏻♀️ :
# ex: what *NOT* to do
# filter the data (note this )
intermediate_obj <- data[data$column1 > 5, ]
# Group by column2
grouped_data <- split(intermediate_obj, intermediate_obj$column2)
# Calculate the mean of column3 within each group
result <- lapply(grouped_data, function(x) {
data.frame(mean_value = mean(x$column3))
})
result <- do.call(rbind, result)Useful functions from tidyverse
filter(): Filter rows based on conditions.select(): Select specific columns.mutate(): Create or modify variables.transmute(): creates a new data frame containing only the specified computationsmutate()1arrange(): Sort rows.group_by(): Group data for aggregation.summarize(): Calculate summary statistics.distinct(): Remove duplicate rows.slice(): Extract specific rows 2rename(): Rename columns.gather(): Convert data from wide to long formatpivot_longer()spread(): Convert data from long to wide formatpivot_wider()pivot_longer(): makes the data frame longer and narrower
pivot_wider(): makes a data frame wider and decreases the number of rowsseparate(): Split a column into multiple columns3drop_na(): Remove rows with missing values.
ymd(),mdy(), etc.: Parse date and time strings.year(),month(), etc.: Extract components from dates.date(): Create date objects.
fct_reorder(): Reorder factor levels based on values.
map(): Apply a function to each element of a list or vector.
map_df(),map_dbl(),map_int(), etc.: Simplify the output to a data frame, double, integer, etc., respectively.across(): apply function(s) to multiple columns
rowwise(): applies functions across columns within one row
read_csv(): Read CSV files.read_table(): Read delimited text files.read_excel(): Read Excel files.
There is not enough time in a single review lecture to go over the details of all of these in justice, so instead we will go through a few examples and use as many as we can along the way. Please make sure to review the necessary lab/lectures to cover the gaps.
Plotting with ggplot
A great resorce for the functionality of ggplot2 can be seen on the Posit website. Notably, you should download the cheatsheet familiarize yourself with it and have it as a resource when creating visualizations.
Problem 1: COVID-19
Countries around the world are responding to an outbreak of respiratory illness caused by a novel coronavirus, COVID-19. The outbreak first started in Wuhan, China, but cases have been identified in a growing number of other locations internationally, including the United States. In this report we explore how the trajectory of the cumulative deaths in a number of countries.
The data come from the coronavirus package, which pulls data from the Johns Hopkins University Center for Systems Science and Engineering (JHU CCSE) Coronavirus repository. The coronavirus package provides a tidy format dataset of the 2019 Novel Coronavirus COVID-19 (2019-nCoV) epidemic. The package is available on GitHub here and is updated daily; see ?coronavirus
For our analysis, in addition to the coronavirus package, we will use the following packages for data wrangling and visualisation.
- tidyverse for data wrangling and visualization
- lubridate package for handling dates
- glue package for constructing text strings
- scales package for formatting axis labels
- ggrepel package for pretty printing of country labels
We will make use of the DT package for interactive display of tabular output which includes a Search bar.
library(coronavirus) # devtools::install_github("RamiKrispin/coronavirus")
library(tidyverse)
library(DT)coronavirusData prep
The data frame called coronavirus in the coronavirus package provides a daily summary of the Coronavirus (COVID-19) cases by country. Each row in the data frame represents a country (or, where relevant, state/province).
Exercise 1: order countries
Let’s create a full list of the countries in the data frame. Write some code (using tidyverse functions) to extract the list of unique countries ordered alphabetically.
# your code goes here:Click for answer
coronavirus %>%
select(country) %>%
arrange(country) %>%
distinct() %>%
datatable()Note that the data provided in this package provides daily number of deaths, confirmed cases, and recovered cases (in the type column). For this report, we will focus on the deaths. We will start by making our selection for the countries we want to explore.
countries <- c(
"China",
"France",
"United Kingdom",
"US",
"Turkey"
)Exercise 2:
Find the total number of deaths in select countries. It may be helpful to split these into subtasks:
subtask 1:
Filter the data frame for deaths in the countries we specified above.
subtask 2:
Calculate the cumulative number of deaths.
click to show answer
coronavirus |>
filter(
type == "death",
country %in% countries
) |>
group_by(country) |>
summarise(sum(cases)) subtask 3:
Let’s rename the column to be a little bit more informative… maybe tol_cases (short for total cases)
click to show answer
coronavirus |>
filter(
type == "death",
country %in% countries
) |>
group_by(country) |>
summarise(tot_cases = sum(cases)) Problem 2: Bechdel
In this mini analysis we work with the data used in the FiveThirtyEight story titled “The Dollar-And-Cents Case Against Hollywood’s Exclusion of Women”. The Bechdel test tests whether the movie features at least two female characters who have a conversation about something other than a man. The binary PASS/FAIL is stored in the binary column with more details of the test result in clean_test: (e.g. ok = passes test, notalk = women don’t talk to each other, nowomen = fewer than two women, …).
Data and packages
We start with loading the packages we’ll use.
library(fivethirtyeight)
library(tidyverse)Your task is to fill in the blanks denoted by ___.
str(bechdel)tibble [1,794 × 15] (S3: tbl_df/tbl/data.frame)
$ year : int [1:1794] 2013 2012 2013 2013 2013 2013 2013 2013 2013 2013 ...
$ imdb : chr [1:1794] "tt1711425" "tt1343727" "tt2024544" "tt1272878" ...
$ title : chr [1:1794] "21 & Over" "Dredd 3D" "12 Years a Slave" "2 Guns" ...
$ test : chr [1:1794] "notalk" "ok-disagree" "notalk-disagree" "notalk" ...
$ clean_test : Ord.factor w/ 5 levels "nowomen"<"notalk"<..: 2 5 2 2 3 3 2 5 5 2 ...
$ binary : chr [1:1794] "FAIL" "PASS" "FAIL" "FAIL" ...
$ budget : int [1:1794] 13000000 45000000 20000000 61000000 40000000 225000000 92000000 12000000 13000000 130000000 ...
$ domgross : num [1:1794] 25682380 13414714 53107035 75612460 95020213 ...
$ intgross : num [1:1794] 4.22e+07 4.09e+07 1.59e+08 1.32e+08 9.50e+07 ...
$ code : chr [1:1794] "2013FAIL" "2012PASS" "2013FAIL" "2013FAIL" ...
$ budget_2013 : int [1:1794] 13000000 45658735 20000000 61000000 40000000 225000000 92000000 12000000 13000000 130000000 ...
$ domgross_2013: num [1:1794] 25682380 13611086 53107035 75612460 95020213 ...
$ intgross_2013: num [1:1794] 4.22e+07 4.15e+07 1.59e+08 1.32e+08 9.50e+07 ...
$ period_code : int [1:1794] 1 1 1 1 1 1 1 1 1 1 ...
$ decade_code : int [1:1794] 1 1 1 1 1 1 1 1 1 1 ...The dataset contains information on ______________ movies released between ____________ and _______________.
Exericse 1:
Create a data frame called bechdel90_10 that subsets the data to included on the movies between 1990 and 2010 inclusively.
Click to show answer
bechdel90_10 <- bechdel %>%
filter(between(year, 1990, 2010))There are ___ such movies.
Exericse 2:
The financial variables we’ll focus on are the following:
budget_2013: Budget in 2013 inflation adjusted dollarsdomgross_2013: Domestic gross (US) in 2013 inflation adjusted dollarsintgross_2013: Total International (i.e., worldwide) gross in 2013 inflation adjusted dollars
And we’ll also use the binary and clean_test variables for grouping.
Let’s take a look at how median budget and gross vary by whether the movie passed the Bechdel test, which is stored in the binary variable.
bechdel90_10 %>%
<function>(___) %>%
<function>(
med_budget = ??,
med_domgross = ??,
med_intgross = ??
)Click for answer
bechdel90_10 %>%
group_by(binary) %>%
summarise(
med_budget = median(budget_2013),
med_domgross = median(domgross_2013, na.rm = TRUE),
med_intgross = median(intgross_2013, na.rm = TRUE)
)Exercise 3:
Next, let’s take a look at how median budget and gross vary by a more detailed indicator of the Bechdel test result. This information is stored in the clean_test variable, which takes on the following values:
ok= passes testdubiousmen= women only talk about mennotalk= women don’t talk to each othernowomen= fewer than two women
In order to evaluate how return on investment varies among movies that pass and fail the Bechdel test, we’ll first create a new variable called roi as the ratio of the gross to budget calculated using:
bechdel90_10 <- bechdel90_10 %>%
<function>(
?? = ??)Click for answer
bechdel90_10 <- bechdel90_10 %>%
mutate(roi = (intgross_2013 + domgross_2013) / budget_2013)Exercise 4:
Which movies have the highest return on investment.
Click for answer
bechdel90_10 %>%
arrange(desc(roi)) %>%
select(title, roi, year)Exercise 5:
Visualization the return on investment by test result in a side-by-side boxplot. Distinguish the tests that pass the test by colour. Add some appropriate labels.
ggplot(data = _____,
mapping = aes()) +
geom_<?>Code
ggplot(data = bechdel90_10,
mapping = aes(x = clean_test, y = roi, color = binary)) +
geom_boxplot() +
labs(
title = "Return on investment vs. Bechdel test result",
x = "Detailed Bechdel result",
y = "___",
color = "Binary Bechdel result"
)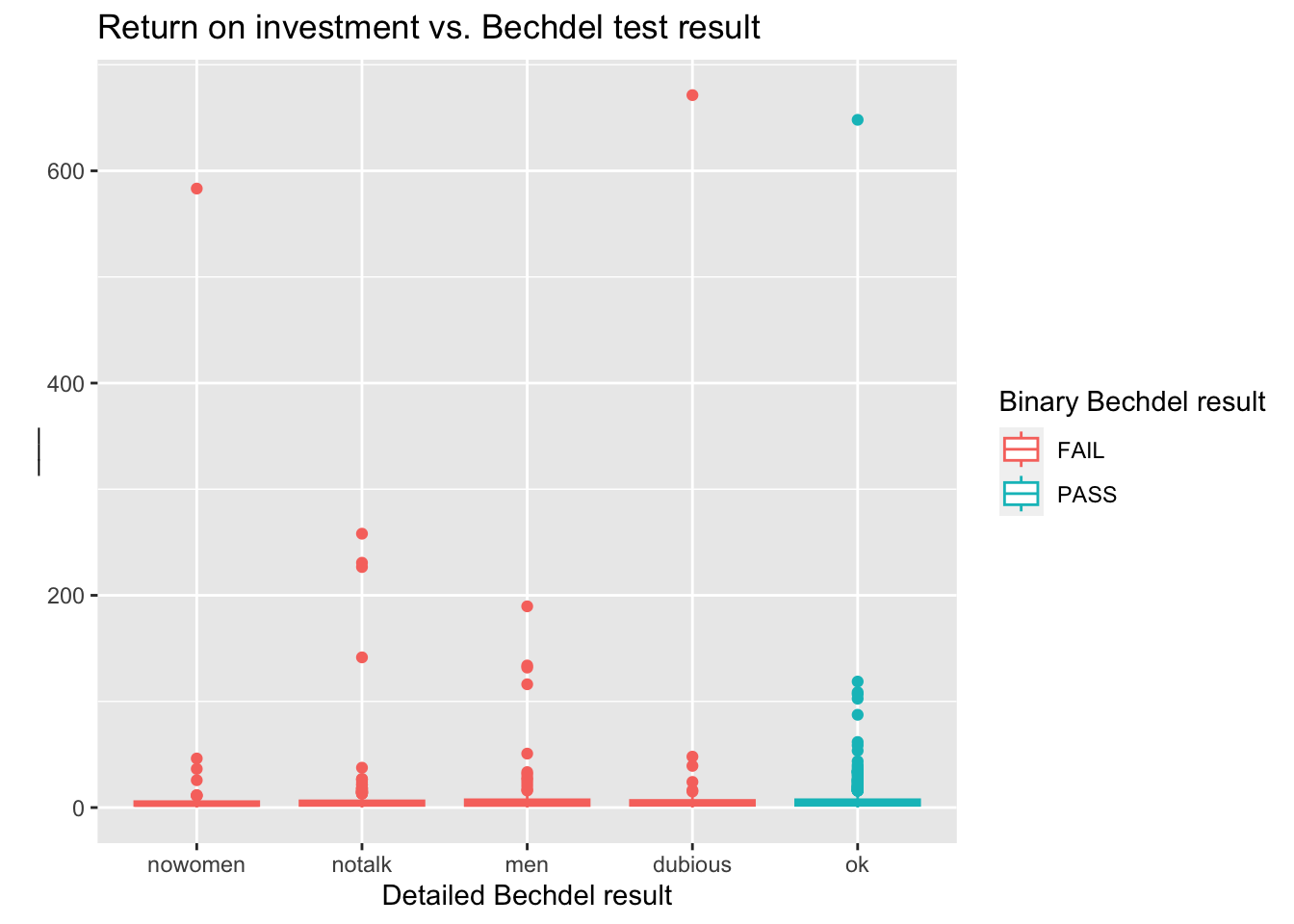
What would be a reasonable label for the y axis?
Exercise 6:
Note that it is very difficult to see the distributions due to a few extreme observations. What are those movies with very high returns on investment, say larger than 400?
Code
bechdel90_10 %>%
filter(roi > 400) %>%
select(title, budget_2013, domgross_2013, year)Exercise 7:
Zooming in on the movies with roi < ___ provides a better view of how the medians across the categories compare:
ggplot(data = bechdel90_10, mapping = aes(x = clean_test, y = roi, color = binary)) +
geom_boxplot() +
labs(
title = "Return on investment vs. Bechdel test result",
subtitle = "___", # Something about zooming in to a certain level
x = "Detailed Bechdel result",
y = "Return on investment",
color = "Binary Bechdel result"
) +
coord_cartesian(ylim = c(0, 15))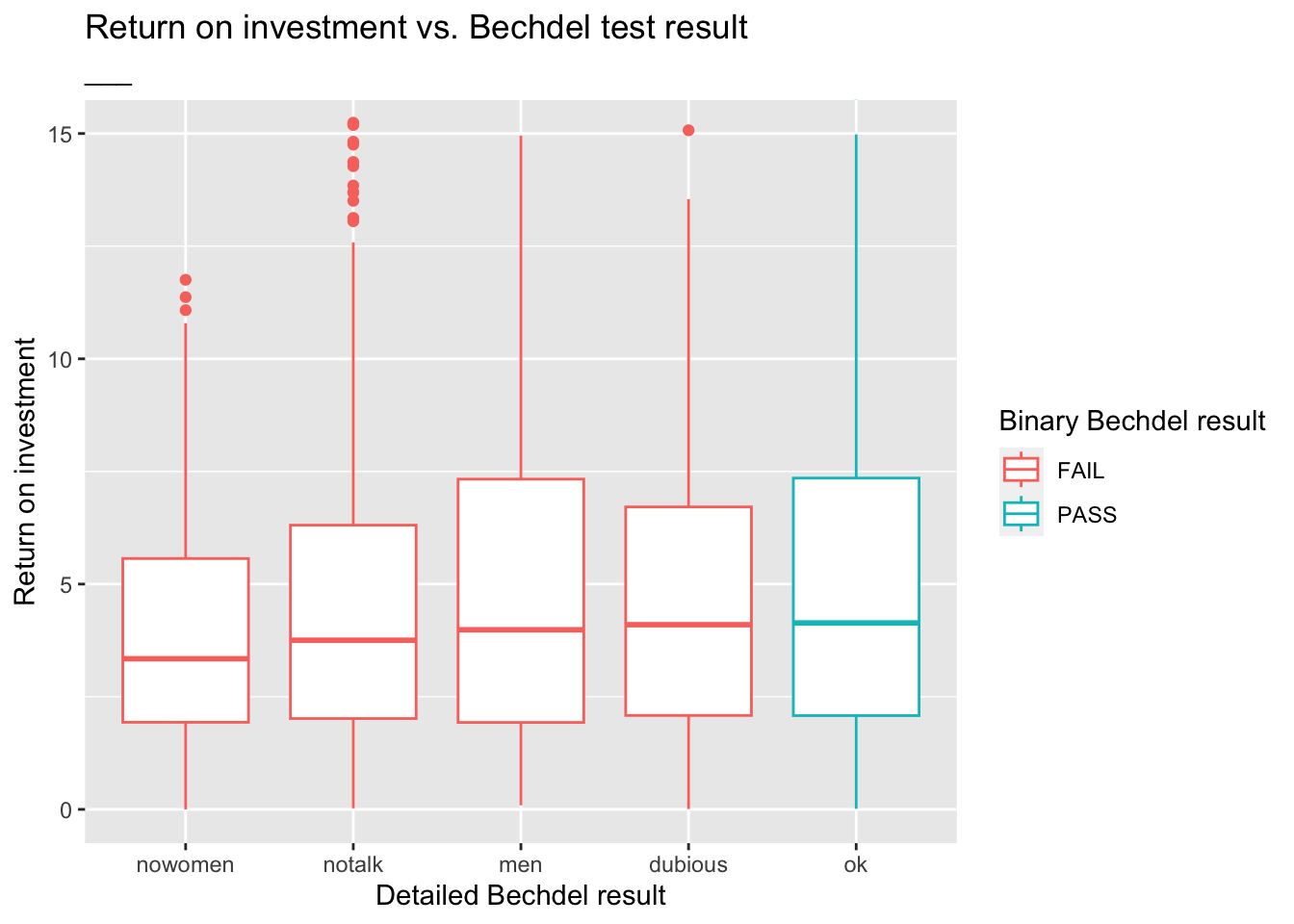
Exercise 3: Statwars
- Glimpse at the starwars data frame.
glimpse(starwars) # from dplyr packageRows: 87
Columns: 14
$ name <chr> "Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Or…
$ height <int> 172, 167, 96, 202, 150, 178, 165, 97, 183, 182, 188, 180, 2…
$ mass <dbl> 77.0, 75.0, 32.0, 136.0, 49.0, 120.0, 75.0, 32.0, 84.0, 77.…
$ hair_color <chr> "blond", NA, NA, "none", "brown", "brown, grey", "brown", N…
$ skin_color <chr> "fair", "gold", "white, blue", "white", "light", "light", "…
$ eye_color <chr> "blue", "yellow", "red", "yellow", "brown", "blue", "blue",…
$ birth_year <dbl> 19.0, 112.0, 33.0, 41.9, 19.0, 52.0, 47.0, NA, 24.0, 57.0, …
$ sex <chr> "male", "none", "none", "male", "female", "male", "female",…
$ gender <chr> "masculine", "masculine", "masculine", "masculine", "femini…
$ homeworld <chr> "Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", "T…
$ species <chr> "Human", "Droid", "Droid", "Human", "Human", "Human", "Huma…
$ films <list> <"The Empire Strikes Back", "Revenge of the Sith", "Return…
$ vehicles <list> <"Snowspeeder", "Imperial Speeder Bike">, <>, <>, <>, "Imp…
$ starships <list> <"X-wing", "Imperial shuttle">, <>, <>, "TIE Advanced x1",…- Create a scatter plot with
masson the y-xis,heighton the x-axis. Colour points by gender and have larger points for younger characters.
Code
ggplot(starwars,
aes(x = height, y = mass, color = gender, size = birth_year)) +
geom_point()Warning: Removed 51 rows containing missing values (`geom_point()`).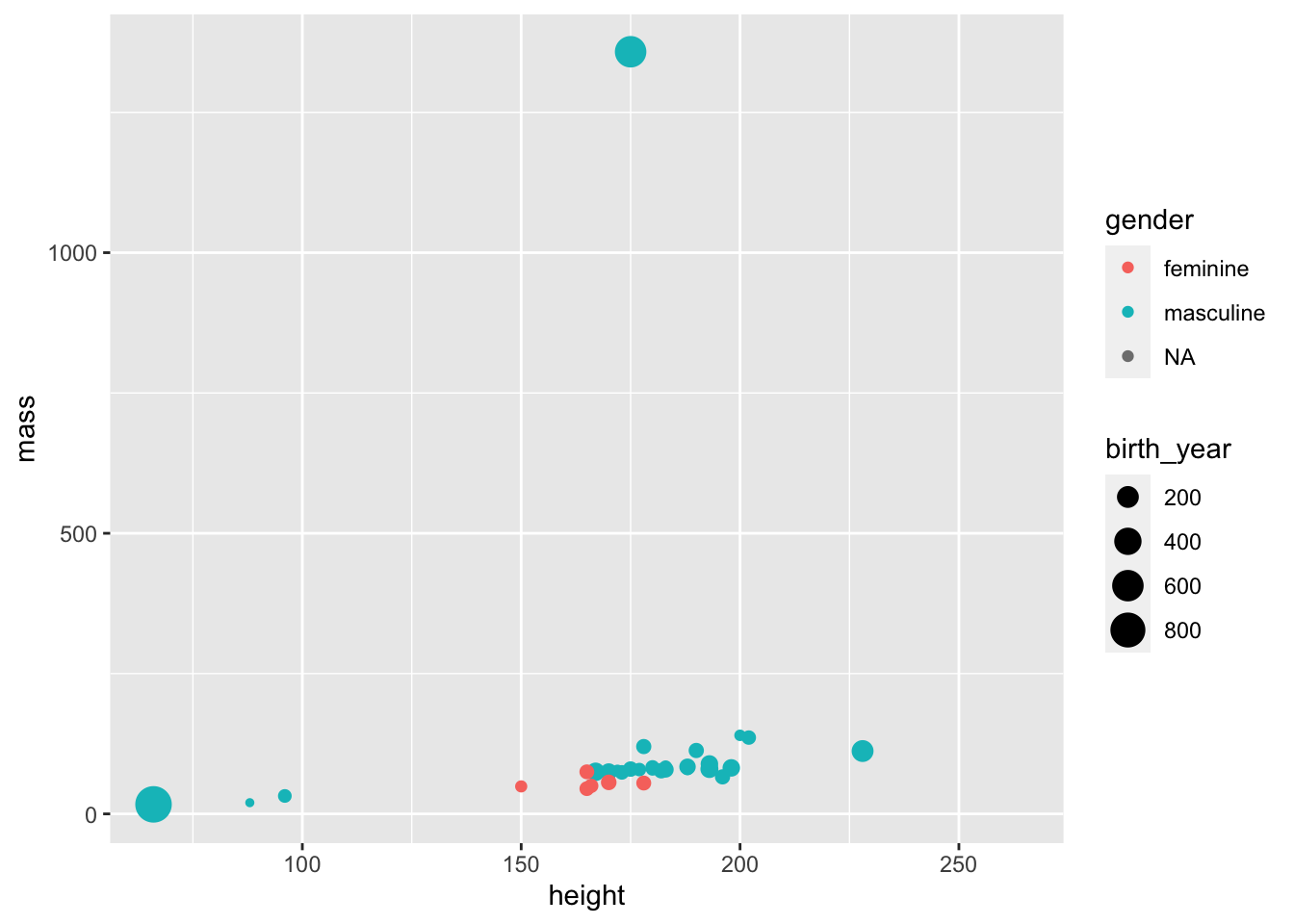
How would you change the above so all the points were coloured to “pink”?
Code
ggplot(starwars,
aes(x = height, y = mass, color = gender, size = birth_year)) +
geom_point(color = "pink")Warning: Removed 51 rows containing missing values (`geom_point()`).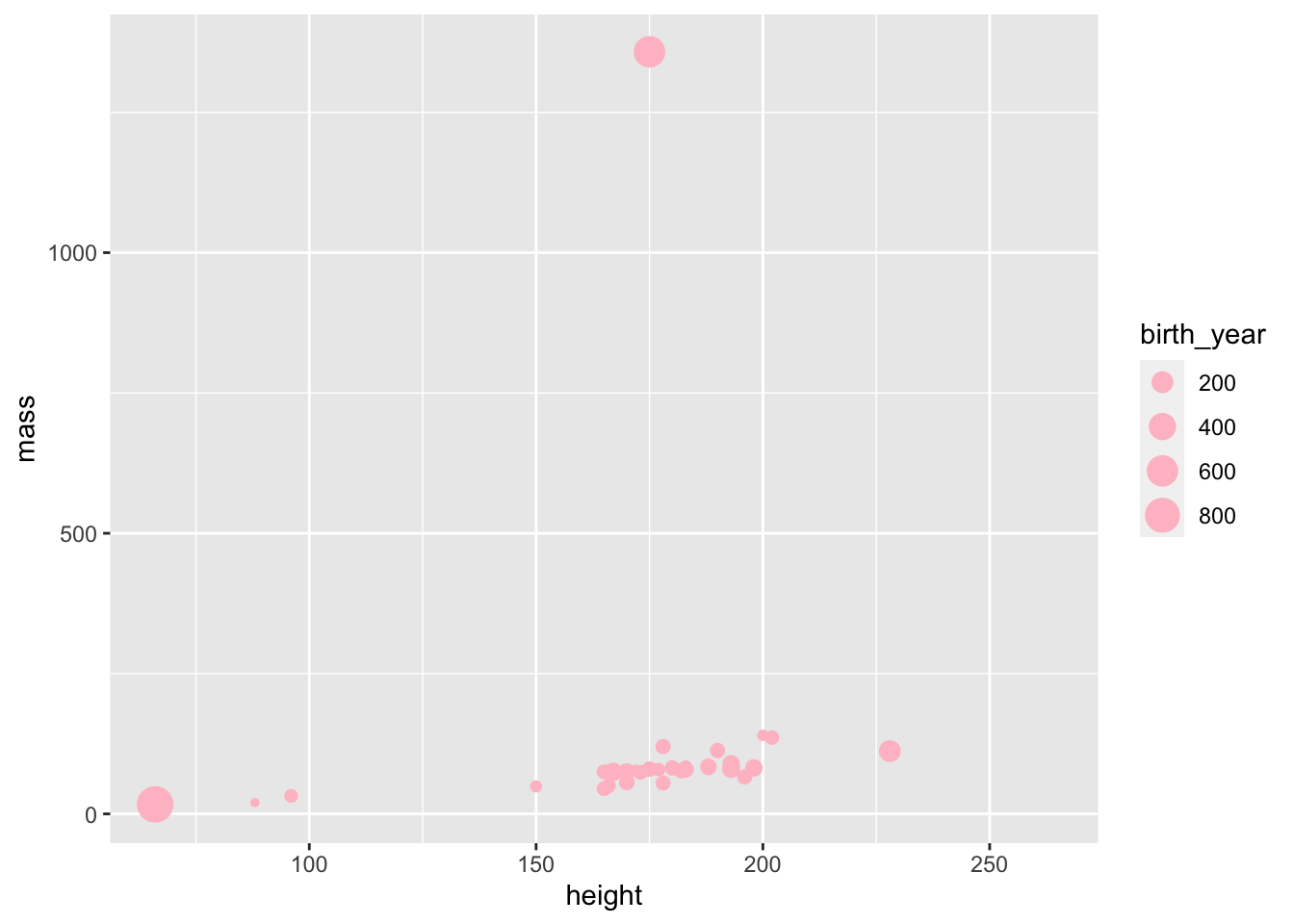
- Add labels for title, x and y axes, and size of points. Uncomment to see the effect.
ggplot(starwars,
aes(x = height, y = mass, color = gender, size = birth_year)) +
geom_point(color = "#30509C") +
labs(
#title = "___",
#x = "___",
#y = "___",
#___
)Warning: Removed 51 rows containing missing values (`geom_point()`).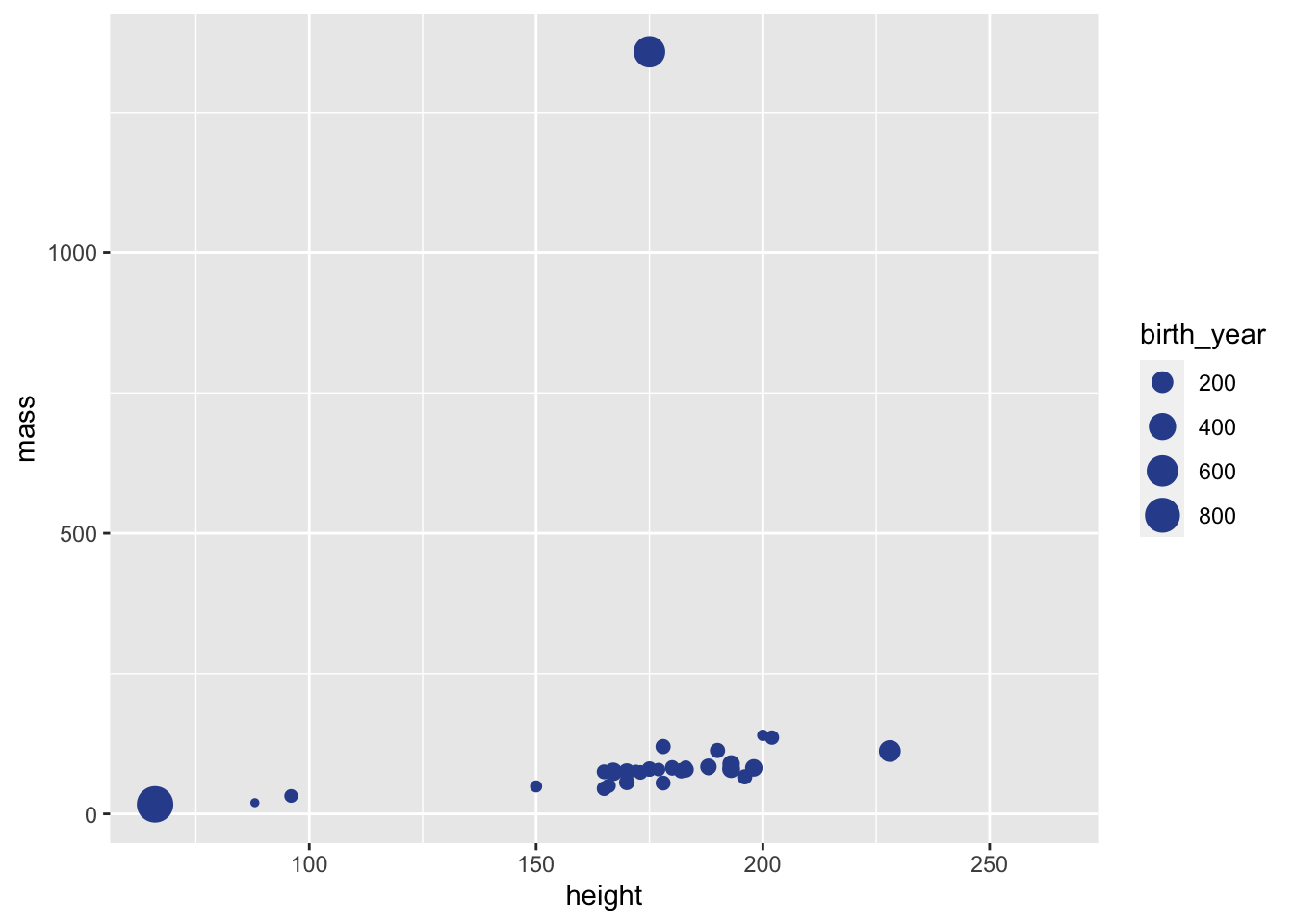
- Pick a single numerical variable and make a histogram of it. Select a reasonable binwidth for it.
(A little bit of starter code is provided below, and the code chunk is set to not be evaluated with eval: false because the current code in there is not valid code and hence the document wouldn’t knit. Once you replace the code with valid code, set the chunk option to eval: true, or remove the eval option altogether since it’s set to true by default.)
ggplot(starwars, aes(___)) +
geom___- Pick a numerical variable and a categorical variable and make a visualization (you pick the type!) to visualization the relationship between the two variables. Along with your code and output, provide an interpretation of the visualization.
Interpretation goes here…
- Pick a single categorical variable from the data set and make a bar plot of its distribution.
- Pick two categorical variables and make a visualization to visualize the relationship between the two variables. Along with your code and output, provide an interpretation of the visualization.
Interpretation goes here…
- Pick two numerical variables and two categorical variables and make a visualization that incorporates all of them and provide an interpretation with your answer.
(This time no starter code is provided, you’re on your own!)
Interpretation goes here…
Exercise: Hotels
The data this week comes from an open hotel booking demand dataset from Antonio, Almeida and Nunes, 2019. These bookings all come from the United states.
# From TidyTuesday: https://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-02-11/readme.md
hotels <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-11/hotels.csv")Exercise 1.
Warm up! Take a look at an overview of the data.
Note: A definition of all variables is given in the Data dictionary section at the end, though you don’t need to familiarize yourself with all variables in order to work through these exercises.
hotelsExercise 2.
Are people traveling on a whim? Let’s see…
Fill in the blanks for filtering for hotel bookings where the guest is not from the US (country code "USA") and the lead_time is less than 1 day.
Note: You will need to set eval=TRUE when you have an answer you want to try out.
hotels %>%
filter(
country ____ "USA",
lead_time ____ ____
)Code
hotels %>%
filter(
country != "USA",
lead_time < 1
)Code
# so there are 6174 bookings where the traveler(s) is deciding to travel on the same day across to an to another country!Exercise 3.
How many bookings involve at least 1 child or baby?
In the following chunk, replace
[AT LEAST]with the logical operator for “at least” (in two places)[OR]with the logical operator for “or”
Note: You will need to set eval=TRUE when you have an answer you want to try out.
hotels %>%
filter(
children [AT LEAST] 1 [OR] babies [AT LEAST] 1
)Code
hotels %>%
filter(
children >= 1 | babies >= 1
)Exercise 4.
You can watch the original creater, Dr. Mine Çetinkaya-Rundel (prolific Statistics/Data Science educator and member at Posit, go through this on her YouTube channel: https://www.youtube.com/watch?v=BXlOd4EYQrI
Do you think it’s more likely to find bookings with children or babies in city hotels or resort hotels? Test your intuition. Using filter() determine the number of bookings in resort hotels that have more than 1 child or baby in the room? Then, do the same for city hotels, and compare the numbers of rows in the resulting filtered data frames.
# add code here
# pay attention to correctness and code styleCode
hotels %>%
filter(
hotel == 'Resort Hotel',
children > 1 | babies >= 1
) %>% nrow()# add code here
# pay attention to correctness and code styleCode
hotels %>%
filter(
hotel == 'City Hotel',
children > 1 | babies >= 1
) %>% nrow()
# same as
hotels %>%
filter(
hotel != 'Resort Hotel',
children > 1 | babies >= 1
) %>% nrow()
## So its more likely that a booking with children or babies in city bookings (which wasn't my guess!)Exercise 5.
Create a frequency table of the number of adults in a booking. Display the results in descending order so the most common observation is on top. What is the most common number of adults in bookings in this dataset? Are there any surprising results?
# add code here
# pay attention to correctness and code styleCode
# to get a frequency table:
hotels %>%
count(adults, sort = TRUE)
# same as:
hotels %>%
select(adults) %>%
group_by(adults) %>%
summarize(numb_bookings = n()) %>%
arrange(desc(numb_bookings))
# so a lot of couples are going to hotels, second highest is single travelers
# it's surprising ot see a few bookings with a large number of adults! eg 26 or moreExercise 6.
Repeat Exercise 5, once for canceled bookings (is_canceled coded as 1) and once for not canceled bookings (is_canceled coded as 0). What does this reveal about the surprising results you spotted in the previous exercise?
# add code here
# pay attention to correctness and code styleCode
# for canceled bookings
hotels %>%
filter(is_canceled == 1) %>%
count(adults, sort = TRUE)
# for bookings that were not cancelled
hotels %>%
filter(is_canceled == 0) %>%
count(adults, sort = TRUE)
# it looks like all of all of these >25 people bookings were all cancelled (perhaps a mistake when booking which they then cancelled)Exercise 7.
Calculate minimum, mean, median, and maximum average daily rate (adr) grouped by hotel type so that you can get these statistics separately for resort and city hotels. Which type of hotel is higher, on average?
# add code here
# pay attention to correctness and code styleCode
hotels %>%
group_by(hotel) %>%
summarize(
min_adr = min(adr),
mean_adr = mean(adr, na.rm = TRUE),
med_adr = median(adr, na.rm = TRUE),
max_adr = max(adr, na.rm = TRUE)
)
# city hotels cost a little bit more on average than resort hotels for example.Exercise 8.
We observe two unusual values in the summary statistics above – a negative minimum, and a very high maximum). What types of hotels are these? Were those booking canceled? Locate these observations in the dataset and find out the arrival date (year and month) as well as how many people (adults, children, and babies) stayed in the room. You can investigate the data in the viewer to locate these values, but preferably you should identify them in a reproducible way with some code.
Hint: For example, you can filter for the given adr amounts and select the relevant columns.
# add code here
# pay attention to correctness and code styleCode
# you can type View(hotels) in your console and investigate
# this question interactively using the filter buttons
hotels %>%
filter(
adr == max(adr) | adr == min(adr)
) %>%
select (
adr, hotel, arrival_date_month, arrival_date_year,
adults, children, babies, is_canceled
)
# it looks like the really low value was not cancelled (maybe an refund situation?)
# the high value was cancelled (perhaps a data entry error)Data dictionary
Below is the full data dictionary. Note that it is long (there are lots of variables in the data), but we will be using a limited set of the variables for our analysis.
| variable | class | description |
|---|---|---|
| hotel | character | Hotel (H1 = Resort Hotel or H2 = City Hotel) |
| is_canceled | double | Value indicating if the booking was canceled (1) or not (0) |
| lead_time | double | Number of days that elapsed between the entering date of the booking into the PMS and the arrival date |
| arrival_date_year | double | Year of arrival date |
| arrival_date_month | character | Month of arrival date |
| arrival_date_week_number | double | Week number of year for arrival date |
| arrival_date_day_of_month | double | Day of arrival date |
| stays_in_weekend_nights | double | Number of weekend nights (Saturday or Sunday) the guest stayed or booked to stay at the hotel |
| stays_in_week_nights | double | Number of week nights (Monday to Friday) the guest stayed or booked to stay at the hotel |
| adults | double | Number of adults |
| children | double | Number of children |
| babies | double | Number of babies |
| meal | character | Type of meal booked. Categories are presented in standard hospitality meal packages: Undefined/SC – no meal package; BB – Bed & Breakfast; HB – Half board (breakfast and one other meal – usually dinner); FB – Full board (breakfast, lunch and dinner) |
| country | character | Country of origin. Categories are represented in the ISO 3155–3:2013 format |
| market_segment | character | Market segment designation. In categories, the term “TA” means “Travel Agents” and “TO” means “Tour Operators” |
| distribution_channel | character | Booking distribution channel. The term “TA” means “Travel Agents” and “TO” means “Tour Operators” |
| is_repeated_guest | double | Value indicating if the booking name was from a repeated guest (1) or not (0) |
| previous_cancellations | double | Number of previous bookings that were cancelled by the customer prior to the current booking |
| previous_bookings_not_canceled | double | Number of previous bookings not cancelled by the customer prior to the current booking |
| reserved_room_type | character | Code of room type reserved. Code is presented instead of designation for anonymity reasons |
| assigned_room_type | character | Code for the type of room assigned to the booking. Sometimes the assigned room type differs from the reserved room type due to hotel operation reasons (e.g. overbooking) or by customer request. Code is presented instead of designation for anonymity reasons |
| booking_changes | double | Number of changes/amendments made to the booking from the moment the booking was entered on the PMS until the moment of check-in or cancellation |
| deposit_type | character | Indication on if the customer made a deposit to guarantee the booking. This variable can assume three categories: No Deposit – no deposit was made; Non Refund – a deposit was made in the value of the total stay cost; Refundable – a deposit was made with a value under the total cost of stay. |
| agent | character | ID of the travel agency that made the booking |
| company | character | ID of the company/entity that made the booking or responsible for paying the booking. ID is presented instead of designation for anonymity reasons |
| days_in_waiting_list | double | Number of days the booking was in the waiting list before it was confirmed to the customer |
| customer_type | character | Type of booking, assuming one of four categories: Contract - when the booking has an allotment or other type of contract associated to it; Group – when the booking is associated to a group; Transient – when the booking is not part of a group or contract, and is not associated to other transient booking; Transient-party – when the booking is transient, but is associated to at least other transient booking |
| adr | double | Average Daily Rate as defined by dividing the sum of all lodging transactions by the total number of staying nights |
| required_car_parking_spaces | double | Number of car parking spaces required by the customer |
| total_of_special_requests | double | Number of special requests made by the customer (e.g. twin bed or high floor) |
| reservation_status | character | Reservation last status, assuming one of three categories: Canceled – booking was canceled by the customer; Check-Out – customer has checked in but already departed; No-Show – customer did not check-in and did inform the hotel of the reason why |
| reservation_status_date | double | Date at which the last status was set. This variable can be used in conjunction with the ReservationStatus to understand when was the booking canceled or when did the customer checked-out of the hotel |
Advanced plotting:
Important Note These advanced plotting options will not be tested on Quiz 2
See full video from Dr. Mine Çetinkaya-Rundel here: https://www.youtube.com/watch?v=sByadx_cgDc
First, knit the document and view the following visualisation. How are the months ordered? What would be a better order? Then, reorder the months on the x-axis (levels of arrival_date_month) in a way that makes more sense. You will want to use a function from the forcats package, see https://forcats.tidyverse.org/reference/index.html for inspiration and help.
hotels %>%
group_by(hotel, arrival_date_month) %>% # group by hotel type and arrival month
summarise(mean_adr = mean(adr)) %>% # calculate mean adr for each group
ggplot(aes(
x = arrival_date_month, # x-axis = arrival_date_month
y = mean_adr, # y-axis = mean_adr calculated above
group = hotel, # group lines by hotel type
color = hotel) # and color by hotel type
) +
geom_line() + # use lines to represent data
theme_minimal() + # use a minimal theme
labs(
x = "Arrival month", # customize labels
y = "Mean ADR (average daily rate)",
title = "Comparison of resort and city hotel prices across months",
subtitle = "Resort hotel prices soar in the summer while ciry hotel prices remain relatively constant throughout the year",
color = "Hotel type"
)`summarise()` has grouped output by 'hotel'. You can override using the
`.groups` argument.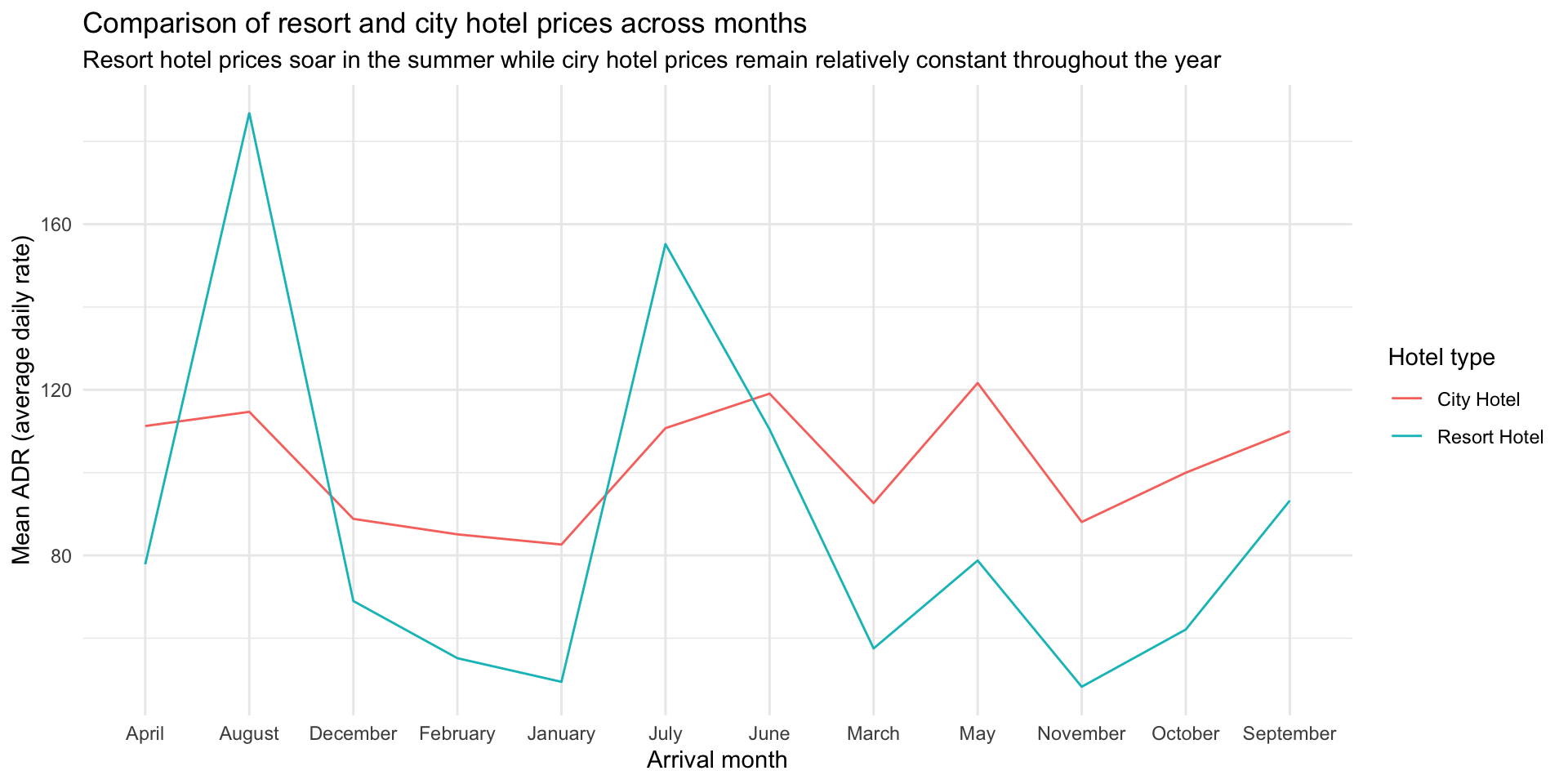
We want to fix some of the problems with this plot:
Goal: Reorder the months in calendar order (as opposed to alphabetically)
To do this we need the arrival_date_month to be releveled so that the first level is January, the second is Feburary, …, and the 12th is December. We we leverage the fact that R has some handy objects4, one being the months names:
month.name [1] "January" "February" "March" "April" "May" "June"
[7] "July" "August" "September" "October" "November" "December" We now use the fct_relevel function to change the order of the levels of arrival_date_month. Now rerunning the code from before we get something more reasonable (we will use the abbreviated version of the months so it’s not so crowded in our plot)
hotels %>%
mutate(arrival_date_month = fct_relevel(arrival_date_month, month.name)) %>%
group_by(hotel, arrival_date_month) %>% # group by hotel type and arrival month
summarise(mean_adr = mean(adr)) %>% # calculate mean adr for each group
ggplot(aes(
x = arrival_date_month, # x-axis = arrival_date_month
y = mean_adr, # y-axis = mean_adr calculated above
group = hotel, # group lines by hotel type
color = hotel) # and color by hotel type
) +
geom_line() + # use lines to represent data
theme_minimal() + # use a minimal theme
labs(
x = "Arrival month", # customize labels
y = "Mean ADR (average daily rate)",
title = "Comparison of resort and city hotel prices across months",
subtitle = "Resort hotel prices soar in the summer while ciry hotel prices remain relatively constant throughout the year",
color = "Hotel type"
)`summarise()` has grouped output by 'hotel'. You can override using the
`.groups` argument.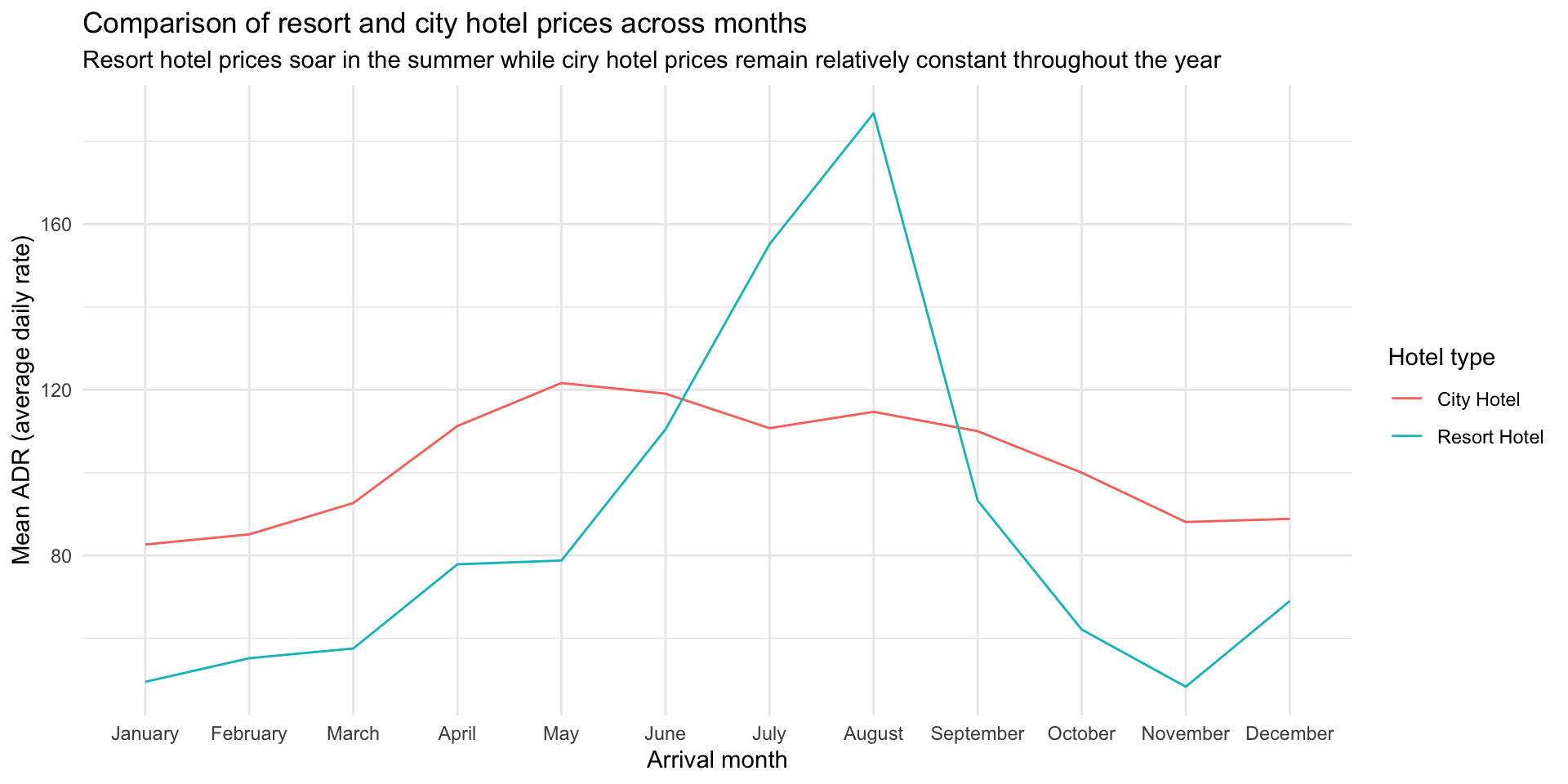
Goal: Change the y-axis label so the values are shown with dollar signs, e.g. $80 instead of 80. You will want to use a function from the scales package, see https://scales.r-lib.org/reference/index.html for inspiration and help.
library(scales)
Attaching package: 'scales'The following object is masked from 'package:purrr':
discardThe following object is masked from 'package:readr':
col_factorhotels %>%
mutate(arrival_date_month = fct_relevel(arrival_date_month, month.name)) %>%
group_by(hotel, arrival_date_month) %>% # group by hotel type and arrival month
summarise(mean_adr = mean(adr)) %>% # calculate mean adr for each group
ggplot(aes(
x = arrival_date_month, # x-axis = arrival_date_month
y = mean_adr, # y-axis = mean_adr calculated above
group = hotel, # group lines by hotel type
color = hotel) # and color by hotel type
) +
geom_line() + # use lines to represent data
theme_minimal() + # use a minimal theme
labs(
x = "Arrival month", # customize labels
y = "Mean ADR (average daily rate)",
title = "Comparison of resort and city hotel prices across months",
subtitle = "Resort hotel prices soar in the summer while ciry hotel prices remain relatively constant throughout the year",
color = "Hotel type"
) +
scale_y_continuous(labels = label_dollar())`summarise()` has grouped output by 'hotel'. You can override using the
`.groups` argument.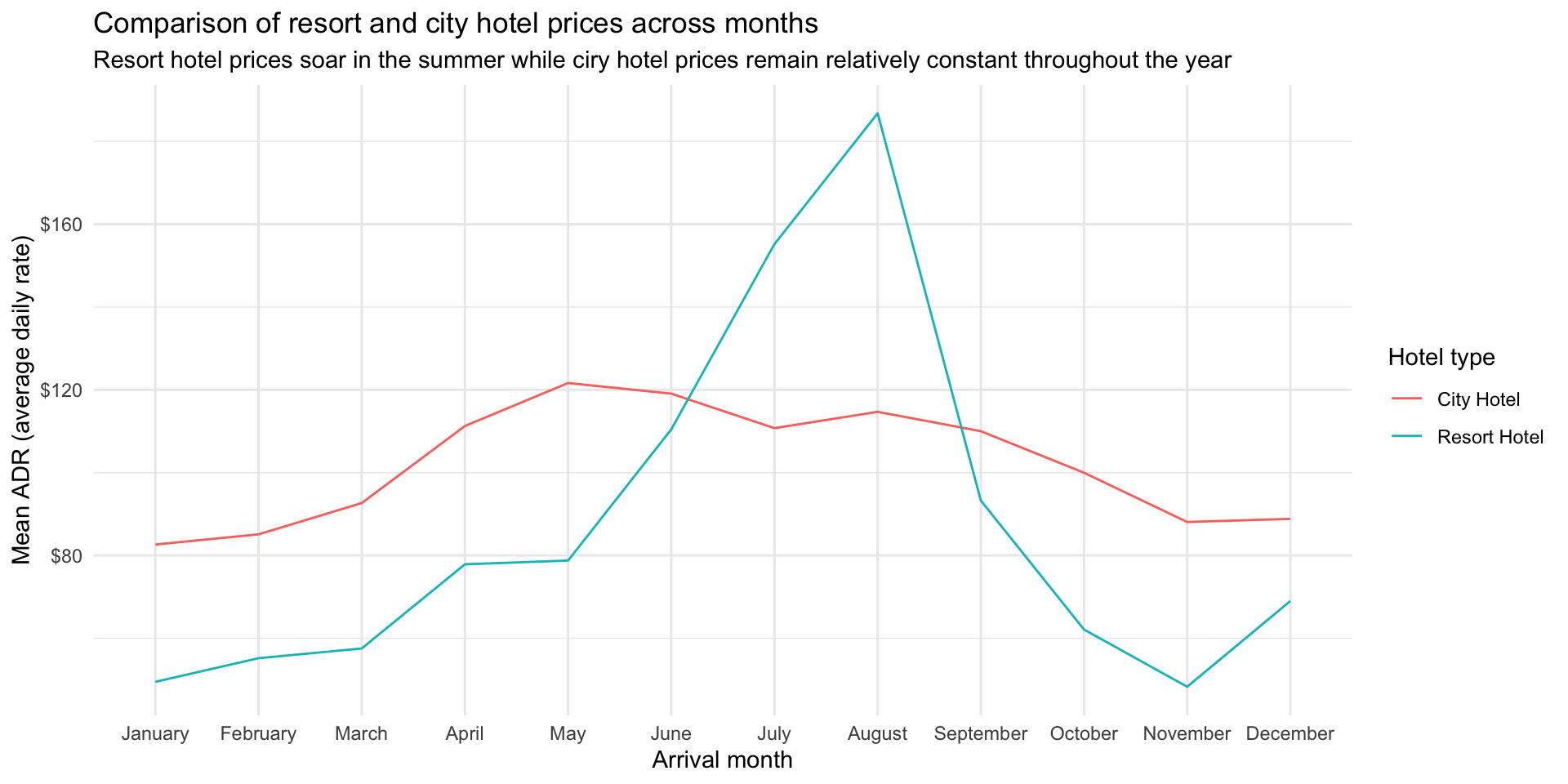
Goal: Prevent the labels from overlapping:
hotels %>%
mutate(arrival_date_month = fct_relevel(arrival_date_month, month.name)) %>%
group_by(hotel, arrival_date_month) %>% # group by hotel type and arrival month
summarise(mean_adr = mean(adr)) %>% # calculate mean adr for each group
ggplot(aes(
x = arrival_date_month, # x-axis = arrival_date_month
y = mean_adr, # y-axis = mean_adr calculated above
group = hotel, # group lines by hotel type
color = hotel) # and color by hotel type
) +
geom_line() + # use lines to represent data
theme_minimal() + # use a minimal theme
labs(
x = "Arrival month", # customize labels
y = "Mean ADR (average daily rate)",
title = "Comparison of resort and city hotel prices across months",
subtitle = "Resort hotel prices soar in the summer while ciry hotel prices remain relatively constant throughout the year",
color = "Hotel type"
) +
scale_y_continuous(labels = label_dollar()) +
scale_x_discrete(guide = guide_axis(n.dodge = 2))`summarise()` has grouped output by 'hotel'. You can override using the
`.groups` argument.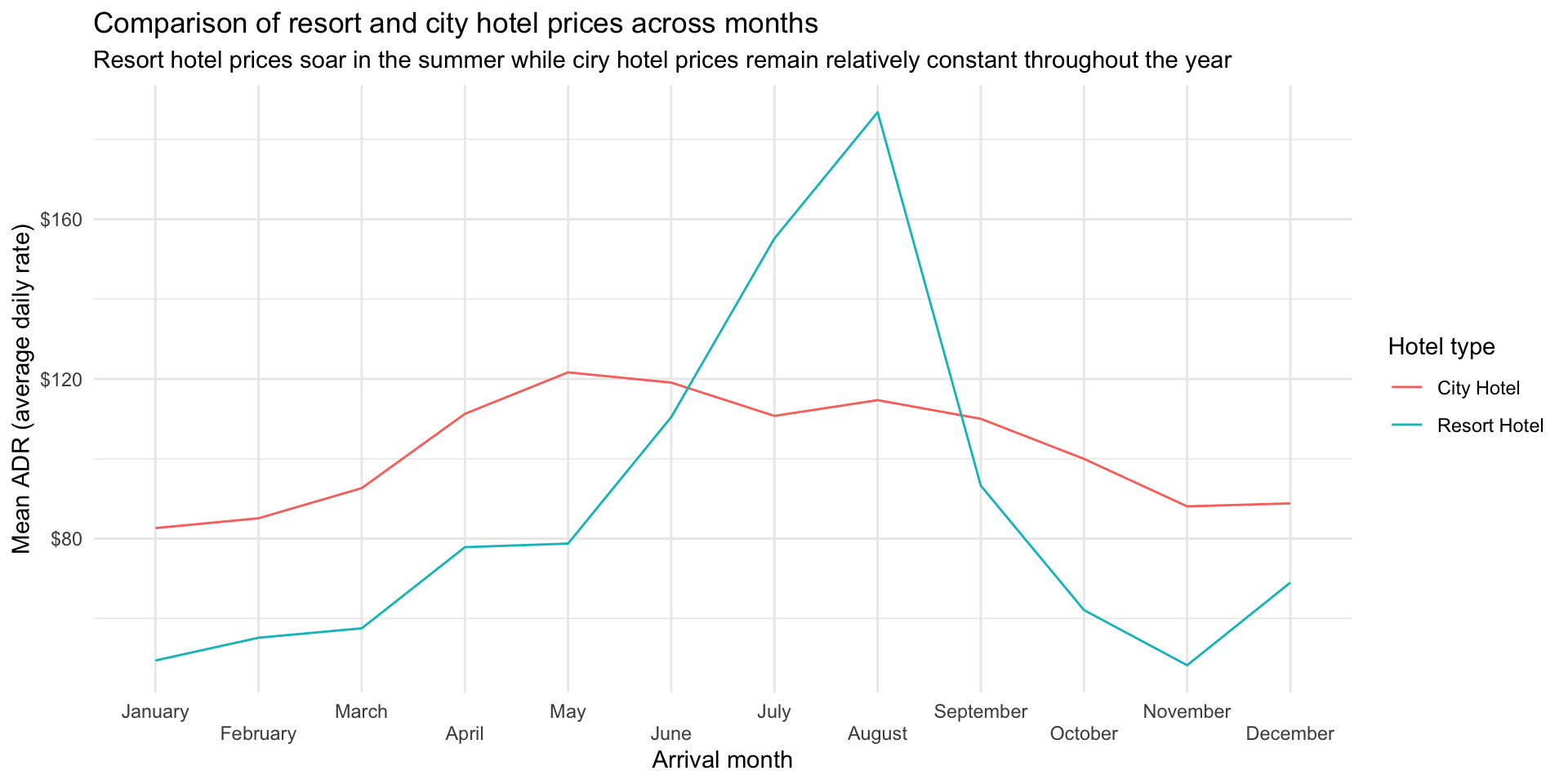
How would you know how to do this?
Well it’s not going to be the case that we can teach you everything. At some point within your Data Science journal, we need to get comfortable with finding answers for ourselves and trust that we have a strong enough foundation be able to these new functions. In this case we might type the following query into Google:
Going to the first link you would find the solution we used (along with another alternative)
Footnotes
It’s superseded because you can perform the same job with
mutate(.keep = "none")↩︎we don’t talk about this function until the classification lab but I thought it made sense to put here for future reference. This we also saw in the classification lab the
slice()function for extracting rows. This function is good for when you want↩︎has been superseded in favour of
separate_wider_position()andseparate_wider_delim()↩︎other examples include:
lettersfor lower-case alphabet, andLETTERSfor uppercase alphabet↩︎